
more on metaculus’ badness
@dubreus replied to your post “IDK who needs to hear this, but Metaculus is…”:
yes, but because the rewards are fairly immaterial, it selects for a community who wants to forecast for its own sake. the randos on metaculus are not your usual randos
I don’t get what you mean by “because the rewards are fairly immaterial.”
Isn’t that also true of twitter polls? Yet they attract randos.
It wouldn’t be true of a real prediction market, but if anything, I’d expect fewer “randos” on account of it.
That aside, I don’t find this kind of defense reassuring w/r/t the trustworthiness of Metaculus.
A lot of my beef with Metaculus is, in fact, precisely this – that if you ask “why would I trust it?”, the answer is some contingent fact about the demographics of the userbase at some point in time, rather than any structural feature of the platform itself.
Making good forecasts is hard. If you want to say you can make good forecasts, you should be able to tell me what mechanism you’re using to make the forecasts good. You should have a hypothesis: “if I do X, I’ll get good forecasts,” and then when I ask, you point to how you’re doing X.
Real prediction markets have such a hypothesis. Their X mechanism may have flaws, but it’s perfectly clear what it is and why someone might expect it to help.
But what is Metaculus’ hypothesis? Its “X”? Based on what the platform actually does as a piece of software, one might guess:
“We will put polls about the future on the internet. The polls are opt-in and anyone can vote on whichever ones they feel like at any time. This will produce good forecasts.”
But this is obvious nonsense – consider the case of twitter polls – so that can’t be it.
We can then observe that “the randos on metaculus are not your usual randos,” which gets us something like
“We will put polls about the future on the internet. The polls are opt-in and anyone can vote on whichever ones they feel like at any time. We will advertise these polls to the kind of people we think are smart. This will produce good forecasts.”
But this still isn’t a trustworthy mechanism! Even if the users on Metaculus right now happen to be smart on average, or good at forecasting on average, that’s a historical accident – there is no feature of the Metaculus platform that guarantees this, or even makes it more likely.
I am asked to take it on faith that the savviness of the userbase has not gotten worse this year than it was last year – or that the users voting on some particular question are about as savvy as those voting on a typical question. If one of these things weren’t true, I would have no way to tell until after I’ve used the forecast and gotten burned.
Among other things, this means Metaculus is exactly the kind of thing that the original formulation of Goodhart’s Law was about:
Any observed statistical regularity will tend to collapse once pressure is placed upon it for control purposes.
The “good demographics” of Metaculus are reliable only so long as no one cares too much about the answers. Once the answers start to have an effect on anything, there is an incentive to vote so as to steer that effect in a desired direction.
And Metaculus has no immune system against this. If a bunch of newbies come in and vote on one question in a politically motivated manner, this is the system working as intended. The “Metaculus community” is just whoever shows up. The people who, in actual fact, show up – savvy or not, politically motivated or not – are the Metaculus community, by definition.
—-
The opt-in nature of the individual polls exacerbates this problem.
Things would be very different if being a “Metaculus forecaster” were a sort of membership with conditions, where you had to vote on every question to stay in the group. That would impose a kind of coherence across questions: if many users feel unqualified to voice opinions on a particular question, that will show up as an unusually broad forecast, and the fact that it is broader than the others will mean the thing it appears to mean. You would be comparing fractions with the same denominator.
But as it is, people can vote on just whatever. Sometimes 1000 people have voted on one question, and only 100 on a very similar question (or a question conditional on the other). These are not two opinions voiced by one “community,” and nothing forces them to cohere. So it is very hard to generalize from facts about one question (or the aggregate over questions) to some other question. Knowing that “Metaculus” got one thing right, or got things right on average, tells me little about any other one of its opinions, because “Metaculus” is a different person every time they say something.
—-
One particular form of this pathology involves changes in the forecasts over time.
Not only is there a different “community” for every question, there is a different “community” for each question at each point in time.
Changes in a forecast can reflect the same forecasters registering new predictions, but they can also reflect new people coming in and registering first-time predictions with different statistics.
It’s tempting to look at those graphs and think “Metaculus changed its mind, it must have done so on the basis of new evidence” (and I see people do this all the time). But it also changes the graph if different people respond to the same evidence.
So these moves have no useful interpretation whatsoever: all they tell you is that that there was a change in the average over whoever showed up. If the change happened because the question got on Hacker News and that drove first-time votes from a bunch of relatively low-information users … then, again, this is the intended behavior of the system. The Metaculus “community” is whoever showed up, at each place and time, and never anything besides.
—-
@dubreus also said:
i also think you’re underselling the part where there’s a commitment to *checking* whether the question ended up happening, a 6-year 1,000 question track record of doing so, and the part where even the top ranked forecasters have similar accuracy to the “dumb community median of randos”
Again, the “anything goes” methodology really limits my willingness to draw any conclusions from this.
Metaculus does have a page where you can review how well it did, in aggregate, over … the questions it decided to ask itself.
But “the questions Metaculus decides to ask itself” is not a natural category, and the questions are chosen so whimsically and unsystematically that an average over them is not very informative.
Compare this to, say, 538. When people talk about 538’s Senate forecasts and ask how good they are, this discussion is grounded in the fact that, if 538 predicts the Senate in a given year, they predict the whole Senate. It’s not like Nate Silver can just pick his favorite subset of the races happening in 2020, and only predict on those, and then pick some other subset in 2022.
This means that aggregates over 538 Senate forecasts are aggregates over the category of Senate races, which is a natural category. Whereas if Nate Silver got to pick which states to predict, then you’d have aggregates over “Senate races conditional on Nate Silver deciding he wanted to predict them.”
In some sense, this is an appropriate category to use when you want to evaluate a current 538 prediction, since it is (by hypothesis) a case where they decided to predict … except that you have to take on faith that older 538 selections are representative of newer ones.
Suppose 538 used to only select states where they thought their model would work well (whatever that means). Then, later, they relax this rule and predict on some states where they don’t expect this. The calibration properties (etc) of their earlier forecasts would not transfer to the new round of predictions – but nothing in their “numerical track record” would give you a hint that this is true.
I’m not going to say this kind of error is unquantifiable, but it is not something people typically quantify (certainly Metaculus doesn’t). Usually people avoid the issue entirely by using transparent and systematic selection rules. (But Metaculus doesn’t.)
—-
In concrete terms, well, people are talking about Metaculus AI forecasts a lot. So I ask, “how good is their track record on AI?”
I go onto that track record page, and … hmm, yes, I can drill down to specific categories, that’s good … so I put in a few AI-related ones and see something like:
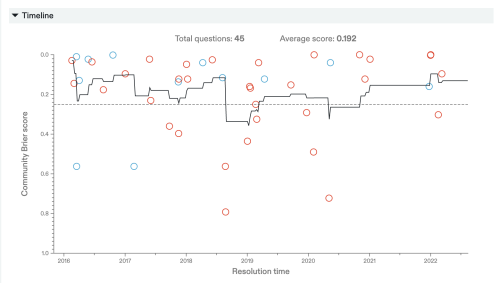
Okay, cool! So … what does that Brier score actually mean? Like, what is this an average over?
One thing that quickly becomes clear is that these categories are noisy. I’m largely getting stuff about the future of AI, but there are some weird ones mixed in:
Will Trump finish the year without mentioning the phrase “Artificial Intelligence”?
[Short-Fuse] Will AbstractSpyTreeBot win the Darwin Game on Lesswrong?
Okay, fine, I add some more filters to weed those out. Now what am I averaging over?
Well, something akin to “Nate Silver’s favorite 17 states” … except here it’s more like “Nate Silver’s favorite 1-2 states, and also 538 only predicted the U.S. Senate once in a single year, and they also predicted the House but only once in some other year, and this year they’re predicting the Israeli parliament.”
Here’s a question that caught my interest:

The “community” kinda thought this would happen in 2018, but it didn’t. Did they think it was going to happen in 2019, then? In 2020 (I think that’s when it really happened)? We don’t know, because they only asked themselves this question once, in 2016-17.
I have no way to assess Metaculus’ quality systematically on any topic area, because it never asks itself questions in a systematic way. Someone could look at the above and think, “maybe Metaculus is overly bullish on self-driving cars.” Are they? I have no idea, because they just ask themselves whichever random self-driving car questions they feel like, with no natural group like “Senate races” over which it would be informative to take an average.
This issue, together with the fluid nature of “the community,” mean I don’t trust any summary statistic about Metaculus to tell me much of anything.
There’s no glue holding this together, giving one of its parts predictive value for the properties of the others. It’s just whatever. Whatever questions people felt like putting on the site, whatever people felt like voting on them at any point in time.
Computing a Brier score over “just whatever” does not give me information about some other “just whatever,” both of them totally whimsical and arbitrary. These statistical tools were made for doing statistics. This is not statistics.
moonblog25 reblogged this from nostalgebraist
cabinet-of-confusion reblogged this from dubreus
lilietsblog liked this
 irynochka liked this
irynochka liked this k-simplex liked this
haintxblue reblogged this from nostalgebraist
cheezbot liked this
 dubreus said:
@nostalgebraist sure, but a numeric forecast can only be said to be bad in the context of other predictors giving better forecasts (in numeric or at least qualitative language). so if there are better sources giving better predictions, we’d actually love to see them, promote them, and compare against our own work.
dubreus said:
@nostalgebraist sure, but a numeric forecast can only be said to be bad in the context of other predictors giving better forecasts (in numeric or at least qualitative language). so if there are better sources giving better predictions, we’d actually love to see them, promote them, and compare against our own work. xenostalgic liked this
nostalgebraist said: @dubreus i’m mainly concerned with the reliability of metaculus in an absolute sense, because i often see people trust it more (in an absolute sense) than i think is warranted. so the answer to “compared to what?” is, compared to all the other sources of information one has about a topic. if none of those other sources take the form of numeric forecasts, well, often there are *no* numeric forecasts on a given topic, and people still seem to get by
- dubreus reblogged this from nostalgebraist and added:
for the sake of transparency, i work at metaculus, but my opinions are my own, not my employers. quick tangent, i think...
bobwoco liked this
transmeowsculine reblogged this from nostalgebraist
 kata4a liked this
kata4a liked this perrydeplatypus reblogged this from nostalgebraist
gvprtskvnis liked this
fnord888 liked this
argumate liked this
 synoddiane liked this
synoddiane liked this lostpuntinentofalantis liked this
sm0lb34nis-gf liked this
 intimate-mirror liked this
intimate-mirror liked this  femmenietzsche liked this
femmenietzsche liked this discoursedrome liked this
jadagul liked this
m-accost liked this
stumpyjoepete liked this
 youarenotthewalrus liked this
youarenotthewalrus liked this  goldsleeps liked this
goldsleeps liked this etirabys liked this
 pretends-to-be-a-catgirl-online liked this
pretends-to-be-a-catgirl-online liked this  transsexualsubstantiation reblogged this from transgenderer
transsexualsubstantiation reblogged this from transgenderer togglesbloggle liked this
theoretically-questionable liked this
guavaorb liked this
 transgenderer reblogged this from nostalgebraist
transgenderer reblogged this from nostalgebraist phenoct liked this
tranxio liked this
youzicha liked this
adjoint-law liked this
 dragonschnitzel liked this
dragonschnitzel liked this tototavros reblogged this from nostalgebraist
@dubreus replied to your post “IDK who needs to hear this, but Metaculus is...”:...yes,...
- Show more notes