AWS Database Blog
Set up highly available PgBouncer and HAProxy with Amazon Aurora PostgreSQL readers
Relational database engines are typically monolithic by design, therefore the easiest method to horizontally scale a workload on them is to scale read operations with multiple read replicas. Some of the strongest motivations for Amazon Aurora PostgreSQL-Compatible Edition adoption include low replication lag and the ability to spin up a reader node in minutes regardless of the size of the database, and make it available behind a common read cluster endpoint. The auto scaling capability to add readers based on thresholds defined for CPU utilization and number of connections is helpful in avoiding over-provisioning of nodes and sustaining read throughput for unpredictable workloads.
However, there are observed inefficiencies with even distribution of connections over a pool of reader nodes when using DNS round-robin routing. This post explains how to utilize a Layer4/Layer 7 load balancer HAProxy, combining it with a lightweight connection pool handler PgBouncer as a sidecar to bring in efficiencies in the system to overcome these issues.
Amazon Aurora
Aurora PostgreSQL is a fully managed, PostgreSQL-compatible, and ACID-compliant relational database engine that combines the speed and reliability of high-end commercial databases. Aurora PostgreSQL makes it cost-effective to set up, operate, and scale your new and existing PostgreSQL deployments.
Aurora reader nodes work well for read scaling because they’re fully dedicated to read operations on your cluster volume, unlike Amazon Relational Database Service (Amazon RDS) for PostgreSQL read replicas, which process write I/O as they consume write ahead logs (WAL) from the primary node. With Aurora, you can have up to 15 readers distributed across Availability Zones. The writer database instance manages write operations, and the cluster volume stores multiple copies (six copies in three Availability Zones) of your data, which is shared among all instances in your Aurora PostgreSQL cluster.
However, despite these strengths in scaling, effectively utilizing all resources of all reader nodes evenly at scale can prove to be challenging, primarily because of two reasons:
- SQL is a flexible query language, and its main advantage lies in the ability to access many records and subject them to various filters for the required data. Different SQL statements in a workload can therefore be vastly different about total runtime as well as I/O as they process data for the desired results. This means it’s difficult to intercept them before runtime to rightly assign instances to balance the load.
- The Aurora cluster reader endpoint implements a DNS round-robin method to distribute connections. This solution doesn’t track reader load or individual clients for the number of requests and response provided for it to have any intelligence to make load balancing over a set of readers. In short, the chances that two consecutive lookups from the same application server yield the same address remains true. This leads to a situation where the read connections can’t get evenly distributed across the read replicas.
The following image depicts a possible scenario of how clients with a JDBC pool using a DNS endpoint may arrive at a reader.
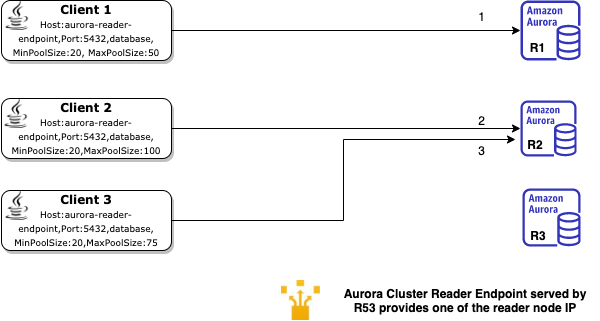
The workflow is as follows (note that the client connections may not happen in sequence):
- Client 1 does a DNS lookup for an Aurora cluster endpoint. Amazon Route 53 provides one of the IPs and Client 1 opens a JDBC connection (the minimum connections defined in the JDBC connection pool config) with Reader 1.
- Client 2 does a DNS lookup for the Aurora cluster reader endpoint and receives the IP of Reader 2, and Client 2 opens a JDBC connection with Reader 2.
- Client 3 does a DNS lookup for the Aurora cluster reader endpoint and receives the IP of Reader 2, and Client 3 opens a JDBC connection with Reader 2.
Assuming you start with a set of clients using connection pooling, the preceding diagram shows how different clients may get the same or a different reader as they look up the Aurora cluster reader endpoint. Clients 2 and 3 receive the Reader 2 endpoint IP address when they look up the Aurora reader endpoint. As a result of the MinPoolSize definitions in the connection pool, the number of connections on the readers are now very different.
The following screenshot shows the number of connections for an Aurora PostgreSQL cluster with auto scaling when tested with a pgbench workload.
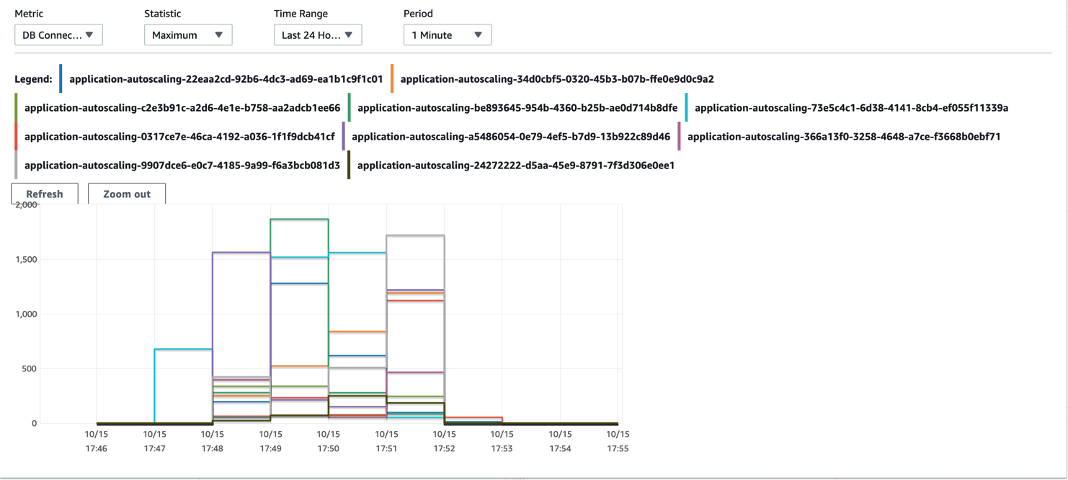
As you can see for the same time period at peak, some instances in the cluster have fewer than 500 sessions, whereas others have over 1,500 sessions. This typically results in higher values for both average CPU utilization and average database connections across the cluster, which are the two metrics used for auto scaling. As such, the system spawns more reader nodes for a workload than actually needed.
Moreover, programming constructs such as connection pools designed to lower context switches negate the load distribution benefit by calling the function (named server) only one time to spawn several connections at once.
Connection pools complement web workloads and are must-haves for high concurrent workloads; they cut down on time taken to initialize and manage connections per thread.
To solve some of these issues, we built Amazon RDS Proxy. Amazon RDS Proxy is a fully managed, serverless, and highly available database proxy for Amazon Relational Database Service (Amazon RDS) that makes applications more scalable, more resilient to database failures, and more secure. Amazon RDS Proxy allows applications to pool and share connections established with the database, improving database efficiency and application scalability. With Amazon RDS Proxy, failover times for Aurora and Amazon RDS databases are reduced by up to 66%, and database credentials, authentication, and access can be managed through integration with AWS Secrets Manager and AWS Identity and Access Management (IAM). Amazon RDS Proxy takes care of the required heavy lifting for provisioning, scaling, maintenance, and configuration of such a system.
However, many customers build self-managed solutions for a database proxy using open-source software such as PgBouncer. This is typically to use custom configuration or tasks such as running databases with non-default ports or to support databases running on Amazon Elastic Compute Cloud (Amazon EC2).
We build a highly available connection pooling setup with PgBouncer and pair it with HAProxy to help provide an additional layer of network intelligence to target a more balanced spray of connections to the Aurora readers.
In principle, you can use the same concept with equivalent connection pooling software for the respective engine for other data stores as well, effectively abstracting the servers behind the Layer 7 endpoint, which allows for dynamic configuration changes. We also look at the ability to use a custom health check and dynamic reconfiguration of a load balancer to consistently check for status, which makes sure that our load balancer solution stays true to the state changes of an Aurora cluster.
Solution overview
The following diagram illustrates our solution architecture.
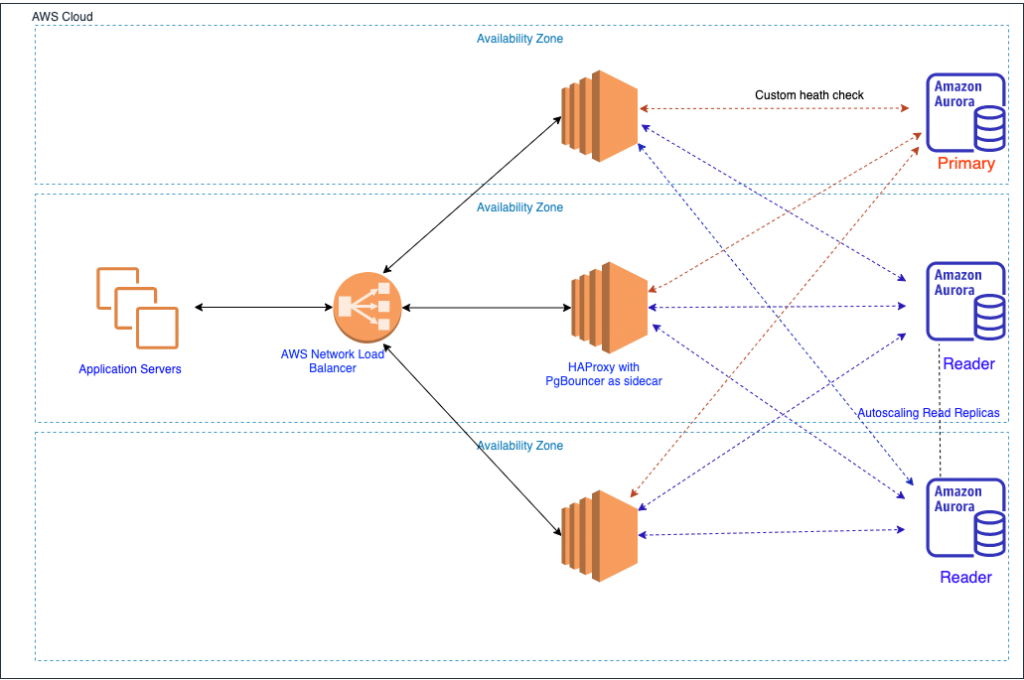
PgBouncer is a connection pooler that lets you optimize database connections so that your applications can perform better. Although PgBouncer can help you manage database connections well, it can’t handle failover or multi-host configurations, which is required for deploying Postgres with high availability. For this reason, we use HAProxy’s TCP load balancing capability along with PgBouncer so that we can deploy a highly available connection tier for Aurora PostgreSQL.
HAProxy is well known for its TCP connection routing capability. For this post, we use the external-check option to perform custom health checks on the reader nodes. HAProxy provides a wide variety of load balancing algorithms. We use the leastconn algorithm for load balancing.
With the leastconn algorithm, the server with the lowest number of connections receives the connection. A round-robin method is performed within groups of servers of the same load to make sure that all servers are used. We recommend using this algorithm if you expect very long sessions, such as LDAP, SQL, or TSE. It’s not ideal for protocols using short sessions such as HTTP. The algorithm is dynamic—server weights may be adjusted on the fly (for example, for slow starts).
This behavior aligns with our objectives, especially because database session times can’t be predicted at the time of connection. This method of load balancing works well when the queries are mostly uniform in nature, such as small, fast, short-duration OLTP queries. With long-running hybrid workloads, although the number of connections are distributed as evenly as possible, the session run times could result in different readers of the cluster experiencing varying database load.
The HAProxy configuration file consists of a four key sections: global, front end, defaults, and backend. The following code is the sample reference backend configuration that we used for our setup:
We use the external-check command to call a custom shell script to implement a health check. In our case, we use this simply to ascertain if the backend server is the primary or secondary. We do this with a simple SQL command calling a PostgreSQL function called pg_is_in_recovery(), which returns a Boolean value to indicate whether it’s the writer or the reader node. This check is needed as insurance to cover us for the following scenarios:
- Aurora failovers are fast, and a reader node can be promoted without notice to a primary. It’s therefore necessary that we keep checking the status of a read replica to make sure that we’re connected to a reader node. Although the writer node is always part of the HAProxy list of servers behind the endpoint, this custom health check ensures we don’t use the writer node for reads and turn off the active flow of sessions against it. Similarly, in the event of a failover, the same script makes sure that the writer (which is now a reader node after a state change) gets its fair share of sessions to serve.
- The monitor_aurora used for reconfiguring HAProxy listeners reads the Aurora cluster state using the Amazon RDS API. When auto scaling provisions the read replicas, they’re immediately visible to the Amazon RDS API. However, there is a lag that can last a few minutes between the creation of the read replica and it being available for queries. The custom health check also ensures that HAProxy doesn’t send a session to the read replica unless it’s ready to accept connections. These and other scripts for the setup are available for download.
Similarly, as explained earlier, database connection pools typically do a single DNS lookup only at startup for the process to pre-provision a large number of sessions to the extent of the number defined in min_pool. This behavior is identical regardless of the application implementation style (application servers, application containers, and even operating systems).
PgBouncer is no different, and spins up as many connections as defined in the min_pool definition in response to the first database connection request it receives. However, as is the case with any connection pool, other parameters such as server_lifetime play an important role in the life of a connection and the number of times it’s reused. When set to a non-zero value for server_lifetime, the time taken to drain and balance connections to other readers is longer. When set to zero, this results in faster effective draining of sessions because each connection is used for a single SQL run. The server_lifetime parameter provides a guideline to PgBouncer to close an unused connection that has been connected longer than this value. This results in new sessions being effectively balanced over other readers based on the active session count at each reader.
However, this negates the advantages of connection pooling on the whole and makes PgBouncer spend additional time creating new database connections, an anti-pattern to what it is primarily designed for.
Therefore, we advise starting with a non-zero value for this parameter and based on observations tune this to get the desired time to balance connections over a new reader that you might deploy. We recommend this setup of PgBouncer with an initial static set of Aurora readers typically sufficient for your workload and use auto scaling with a high threshold as insurance to hold off any unpredictable sudden spikes over your normal utilization.
Another important setting is server_check_query, which we use to make sure that the connections aren’t handed back to application servers before checking their validity. This is similar to the validate or validate on match feature present in some connection pool frameworks. This acts as insurance against handing off old dead sessions to the application. The following is a sample configuration:
For the purposes of high availability, we use a single Network Load Balancer (NLB) in this setup as a way to abstract servers with the HAProxy and PgBouncer setup in the three Availability Zones behind it. We also make sure that we don’t put in place stickiness so that application server-initiated sessions connect with a random set of servers behind the NLB. This ensures that failure of an Amazon EC2 server behind the NLB doesn’t affect all connections of a single application server.
Dynamic reconfiguration of HAProxy
One of the key reasons to rely on HAProxy for this setup is the ability to reload and effectively configure the proxy without dropping existing connections. HAProxy has made notable improvements around this since version 1.8. We recommend that you build HAProxy from sources on a stable release greater than 2.0.
As stated before, although we can automate and add readers back to the HAProxy to make the entire setup dynamic, the dynamic configuration is to help keep maintenance tasks to a minimum when you add readers to the static set as part of a growing workload.
The key to the setup is the configuration of the Unix systemd launch unit configuration parameters for HAProxy. Because we use this setup for multiple Aurora clusters, we need to ensure that a configuration directory is passed as an argument to the binary and not a single file. This makes sure that we can contain the configuration of a single Aurora cluster in independent files. Similarly, the command for reload in the launch configuration needs to be set correctly, otherwise each reload of HAProxy results in connection resets. The following code is a sample file, as deployed on Amazon Linux 2 with systemd-sysv 219-57.amzn2.0.12:
Although PgBouncer can exist on its own server, we merged the deployment for two reasons:
- To reduce management complexity of managing HAProxy to PgBouncer routing
- To reduce network latency by saving a network hop for each database connection
Finally, we used a shell script triggered by the Unix cron scheduler to query Amazon RDS APIs to monitor the cluster state at each invocation, detect changes, and initiate a HAProxy reload to adapt to the new read replicas. The reference code for the shell script used to monitor state changes is available for download.
Be aware that the Amazon EC2 servers hosting PgBouncer and HAProxy need to be attached to an IAM role allowing it to call the DescribeDBClusters and DescribeDBInstances APIs only. The following code is a sample IAM role for Amazon EC2:
The number of servers behind the NLB in this case is to ensure Availability Zone survivability only. We recommend that you size the EC2 instance based on the number of connections being handled and scale vertically if required. An AWS Nitro System-based virtual machine with sufficient network bandwidth such as c5n and m5n instance types is ideal for such setups. Connection pooling and auto scaling of the EC2 instance in this case can have negative effects on the DB server. Multiple instances spawning a large number of connections can possibly overwhelm the database.
We set up a simple pgbench-based test to understand if our setup provided any advantages or efficiencies. To mimic an auto scaling set of application servers, we spawned a new pgbench process to test the DB endpoint with a fresh set of 300 connections every 10 minutes, and set it to run for a maximum duration of 1,800 seconds. We performed the same test on the Aurora cluster endpoint for comparison.
Although the overall network latency jumped from 1–1.25 milliseconds to 3–4 milliseconds, we saw that the current setup resulted in fewer reader nodes being spawned. Additionally, the maximum number of connections created within the time period decreased significantly for the PgBouncer and HAProxy setup. The following graphs show the differences between Amazon CloudWatch metrics.
The first graph is the number of database connections without PgBouncer and HAProxy.
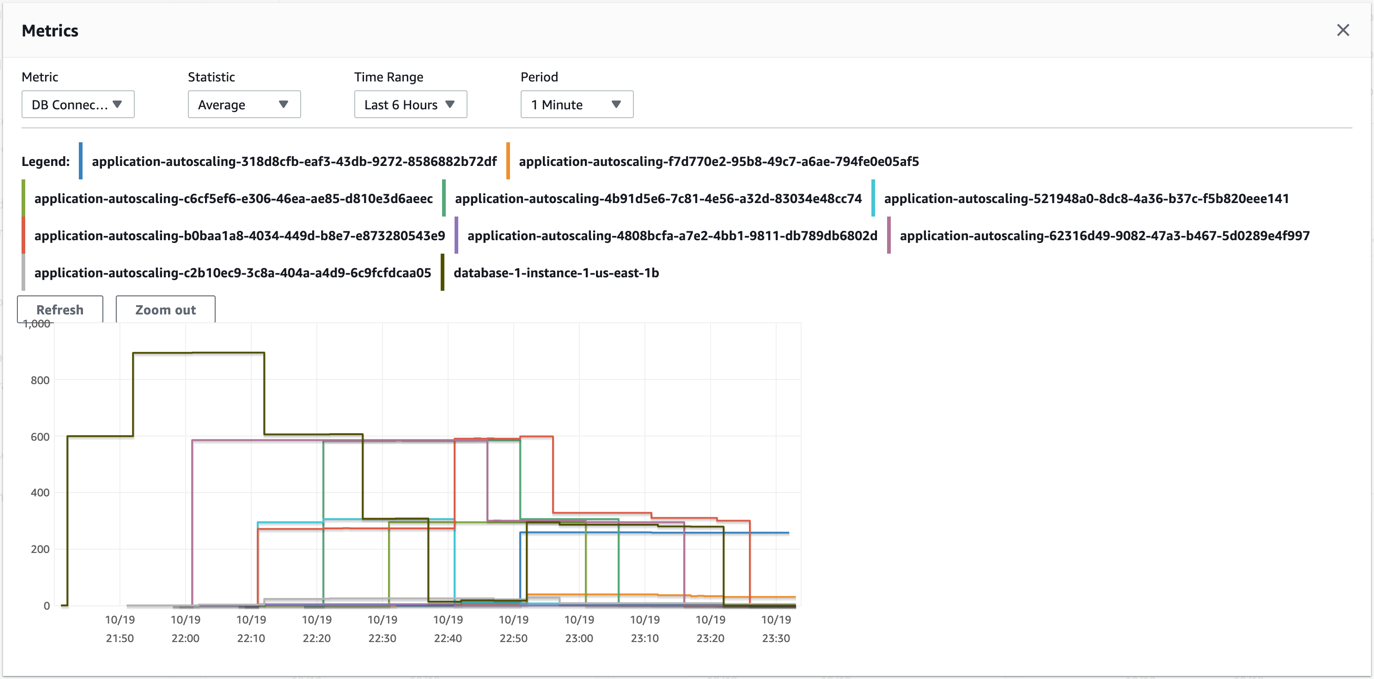
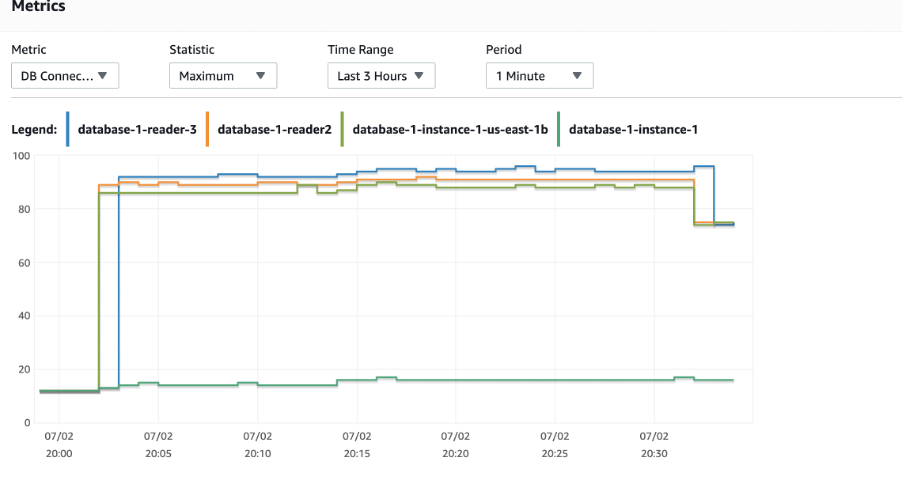
The following graph is with PgBouncer and HAProxy.
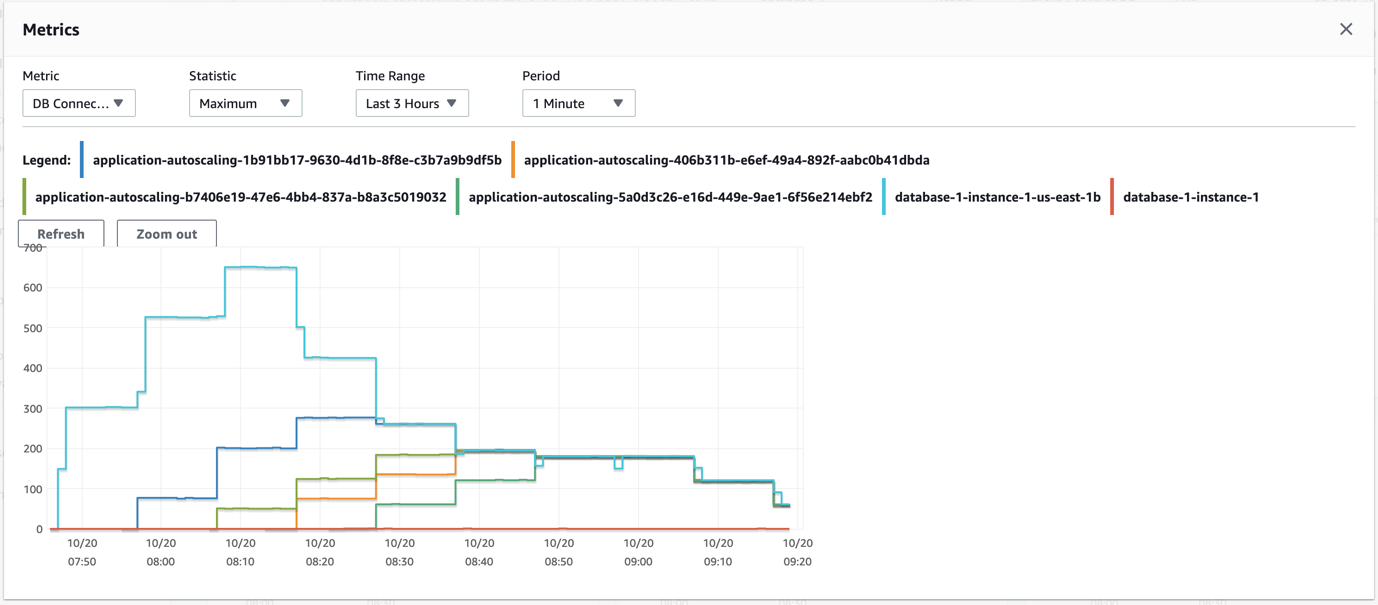
The testing with an Aurora cluster reader endpoint resulted in Aurora provisioning 10 reader nodes compared to 4 with the PgBouncer and HAProxy setup. Additionally, for the PgBouncer and HAProxy setup, the database connections peak but are relatively lower than the number of connections to the Aurora reader endpoint without this setup. It took about 20 minutes into the test for the connections to be distributed.
When tested against a static set of readers, the setup performs better and we see an overall reduction of connections. This test was conducted with server_lifetime set to 5.
We recommend that you set the Aurora auto scaling threshold appropriately, ideally to a number where the workload provides sufficient time for more reader nodes to be added to the cluster before its peak. This is because of the delay time from the creation of the reader node to it being available for active querying. As more servers get added to the cluster, HAProxy can perform an almost perfect balance in terms of number of connections distributed over the cluster. This is reassuring because real-world workloads typically have queries with varying lifetimes.
For operational purposes, we recommend that you use tools like AWS Systems Manager, Ansible, or Chef to manage the default configurations for PgBouncer and HAProxy that are consistent across sets of EC2 instances in the different Availability Zones behind the NLB. We also recommend that you create dashboards in CloudWatch for NLB client resets, target resets, Amazon EC2 CPU utilization, network throughput, Aurora cluster-level database connections, and reader node CPU utilization, and set up required alarms.
Keep in mind that different read replicas in an Aurora cluster could be at various points or latency from the primary. Not all application use cases behave well in such conditions, so it’s necessary to test your workload with the setup at scale and get acceptance from both application developers and business users of the system.
Conclusion
In this post, we showed how HAProxy and PgBouncer helps effectively load balance the connections to Aurora reader nodes.
Workloads that have a high number of read queries but are short-lived can benefit from such an architecture. This also works well for read-only workloads such as reporting, which primarily rely on read replicas. This solution can help sustain seasonal highs and unpredictable increases in workload.
To learn more about Aurora auto scaling, check out Using Amazon Aurora Auto Scaling with Aurora replicas.
About the Author
 Gopalakrishnan Subramanian is a Database Specialist solutions architect at Amazon Web Services. He works with our customers to provide guidance and technical assistance on database projects, helping them improving the value of their solutions when using AWS
Gopalakrishnan Subramanian is a Database Specialist solutions architect at Amazon Web Services. He works with our customers to provide guidance and technical assistance on database projects, helping them improving the value of their solutions when using AWS
 Satheesh Kumar is a Senior Solutions Architect based out of Bangalore, India. He works with enterprise customers to help them build solutions using AWS services.
Satheesh Kumar is a Senior Solutions Architect based out of Bangalore, India. He works with enterprise customers to help them build solutions using AWS services.