A few recent Arxiv papers and some recent conversations during my lectures made me realize that some optimization people might not be fully aware of important details on SGD when used on functions where the minimizer can be arbitrarily far from the initialization or even in the case when the minimizer does not exist. So, let’s talk about it.
First of all, when does this happen? Well, in machine learning it is very common. For example, if you run logistic regression on a separable dataset, or SGD with universal kernels and no repeated data points, or even in deep learning when we assume the so-called interpolation assumption and use cross-entropy + softmax. In all these cases, the minimizer does not exist because we can make the training error arbitrarily close to  by increasing the norm of
by increasing the norm of 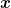 and keeping its direction fixed. In more intuitive terms, we can say that the minimizer is “at infinity”.
and keeping its direction fixed. In more intuitive terms, we can say that the minimizer is “at infinity”.
So, is this a weak or a strong assumption? I’ll let you decide, but for sure if you believe that the interpolation assumption is reasonable, then you also have to believe that assuming the existence of minimizers might not be reasonable in machine learning…

What happens to Stochastic Gradient Descent (SGD) on convex functions in these cases? Consider for simplicity the cases that the stochastic subgradients are bounded by  and use SGD with learning rate
and use SGD with learning rate  starting from
starting from  . (Of course, you can use weaker assumptions, but the core idea will stay the same.) Then, if we take a look at the rates people normally state, we have
. (Of course, you can use weaker assumptions, but the core idea will stay the same.) Then, if we take a look at the rates people normally state, we have
![\displaystyle \mathop{\mathbb E}[f(\bar{{\boldsymbol x}}_T)]-f({\boldsymbol x}^\star) \leq \frac{L}{2\sqrt{T}}\left(\frac{\|{\boldsymbol x}_1-{\boldsymbol x}^\star\|^2}{\alpha}+ \alpha\right),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5Bf%28%5Cbar%7B%7B%5Cboldsymbol+x%7D%7D_T%29%5D-f%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29+%5Cleq+%5Cfrac%7BL%7D%7B2%5Csqrt%7BT%7D%7D%5Cleft%28%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+x%7D_1-%7B%5Cboldsymbol+x%7D%5E%5Cstar%5C%7C%5E2%7D%7B%5Calpha%7D%2B+%5Calpha%5Cright%29%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
where  is the average of the iterates,
is the average of the iterates, 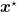 is the optimal solution, and
is the optimal solution, and  is the usual hyperparameter in the learning rate that you have to choose. From the rate, we might be tempted to think that if is really far (“in a galaxy far, far away…”), the rate becomes arbitrarily bad. Even worse, we might be tempted to think that if does not exist, that is it is at infinity, the bound becomes vacuous and we cannot guarantee anything. Now, suppose that your algorithm requires an upper bound on
is the usual hyperparameter in the learning rate that you have to choose. From the rate, we might be tempted to think that if is really far (“in a galaxy far, far away…”), the rate becomes arbitrarily bad. Even worse, we might be tempted to think that if does not exist, that is it is at infinity, the bound becomes vacuous and we cannot guarantee anything. Now, suppose that your algorithm requires an upper bound on  to properly function and its rate depends on it, what would happen? In the best case, the convergence guarantee would be vacuous, in the worst case you would not be even able to run the algorithm! Yet, one might not be worried thinking that SGD has the same behavior.
to properly function and its rate depends on it, what would happen? In the best case, the convergence guarantee would be vacuous, in the worst case you would not be even able to run the algorithm! Yet, one might not be worried thinking that SGD has the same behavior.
If you believe any of the above, it might be the case that you missed some very important details of the theory of SGD. So, let’s try to make some clarity on this point.
It turns out that the above rate is not the best we can prove. What we can actually prove is
![\displaystyle \mathop{\mathbb E}[f(\bar{{\boldsymbol x}}_T)]- f({\boldsymbol u}) \leq \frac{L}{2\sqrt{T}}\left(\frac{\|{\boldsymbol x}_1-{\boldsymbol u}\|^2}{\alpha}+ \alpha\right), \forall {\boldsymbol u} \in {\mathbb R}^d~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5Bf%28%5Cbar%7B%7B%5Cboldsymbol+x%7D%7D_T%29%5D-+f%28%7B%5Cboldsymbol+u%7D%29+%5Cleq+%5Cfrac%7BL%7D%7B2%5Csqrt%7BT%7D%7D%5Cleft%28%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+x%7D_1-%7B%5Cboldsymbol+u%7D%5C%7C%5E2%7D%7B%5Calpha%7D%2B+%5Calpha%5Cright%29%2C+%5Cforall+%7B%5Cboldsymbol+u%7D+%5Cin+%7B%5Cmathbb+R%7D%5Ed%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
The reason is simple: in the entire proof, we never used any property of the minimizer, so we can state the convergence with respect to any arbitrary point. So, the critical difference is that this holds for any 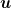 rather than only for . So, now this implies a non-vacuous guarantee even when does not exist. In fact, let me rewrite it as
rather than only for . So, now this implies a non-vacuous guarantee even when does not exist. In fact, let me rewrite it as
![\displaystyle \mathop{\mathbb E}[f(\bar{{\boldsymbol x}}_T)] \leq \frac{\alpha L}{2\sqrt{T}} + \min_{{\boldsymbol u}} \ f({\boldsymbol u})+\frac{L\|{\boldsymbol x}_1-{\boldsymbol u}\|^2}{2\alpha \sqrt{T}} ~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5Bf%28%5Cbar%7B%7B%5Cboldsymbol+x%7D%7D_T%29%5D+%5Cleq+%5Cfrac%7B%5Calpha+L%7D%7B2%5Csqrt%7BT%7D%7D+%2B+%5Cmin_%7B%7B%5Cboldsymbol+u%7D%7D+%5C+f%28%7B%5Cboldsymbol+u%7D%29%2B%5Cfrac%7BL%5C%7C%7B%5Cboldsymbol+x%7D_1-%7B%5Cboldsymbol+u%7D%5C%7C%5E2%7D%7B2%5Calpha+%5Csqrt%7BT%7D%7D+%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
What does it mean? Well, it means that the rate SGD guarantees is better than what one might have thought. Indeed, we can guarantee that the value of the objective function will be at most  plus the value of the minimum of a regularized function, where the strength of the regularization depends on the number of iterations and . Take a moment to digest this, because this is deeper than it looks at first sight. The above says that it might not matter how far might be, indeed it might also be at infinity! Of course, a similar reasoning also holds when the minimizer does exist but it is far, far away. So, this is not a corner case, but rather it covers a big chunk of the interesting cases we encounter. Indeed, if the optimal solution is not far and the Lipschitz constant is relatively small, then the initial point would be already a good solution to the optimization problem. Let me also add that this is exactly the reason why the learning rate acts as a regularizer when you use SGD in only one pass over your data. But this is another story.
plus the value of the minimum of a regularized function, where the strength of the regularization depends on the number of iterations and . Take a moment to digest this, because this is deeper than it looks at first sight. The above says that it might not matter how far might be, indeed it might also be at infinity! Of course, a similar reasoning also holds when the minimizer does exist but it is far, far away. So, this is not a corner case, but rather it covers a big chunk of the interesting cases we encounter. Indeed, if the optimal solution is not far and the Lipschitz constant is relatively small, then the initial point would be already a good solution to the optimization problem. Let me also add that this is exactly the reason why the learning rate acts as a regularizer when you use SGD in only one pass over your data. But this is another story.
Note that I wrote  and not
and not  because
because  has always a minimizer for any convex
has always a minimizer for any convex  because
because  is strongly convex in and convex + strongly convex = strongly convex.
is strongly convex in and convex + strongly convex = strongly convex.
So, we have a non-vacuous bound in all cases, but how good is this? We have to calculate the expression of the minimum over for each specific case. To make it more concrete, let’s consider a simple example: logistic regression on a separable dataset. So,

where 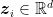 are your input data and
are your input data and 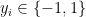 the corresponding labels. Let’s also consider the simplest stochastic oracle for this problem: in each iteration, we take one training sample
the corresponding labels. Let’s also consider the simplest stochastic oracle for this problem: in each iteration, we take one training sample  at random. Now, if the problem is linearly separable, it means that there exists
at random. Now, if the problem is linearly separable, it means that there exists  such that
such that  for all the samples in your training set. I want to stress that is not the optimal solution. Instead, this means that
for all the samples in your training set. I want to stress that is not the optimal solution. Instead, this means that  goes to 0 when
goes to 0 when  . In other words,
. In other words,  is the direction of the “optimal solution at infinity”. In this case, we also have
is the direction of the “optimal solution at infinity”. In this case, we also have  .
.
What is the guarantee of SGD in this case? For simplicity, let’s set  , the general case is equally simple. The first guarantee, the one that assumes the existence of , would be clearly vacuous. However, the second one is still valid, but it is not completely clear what it guarantees. So, consider the minimization in the right hand side and let’s massage it a little bit: For any
, the general case is equally simple. The first guarantee, the one that assumes the existence of , would be clearly vacuous. However, the second one is still valid, but it is not completely clear what it guarantees. So, consider the minimization in the right hand side and let’s massage it a little bit: For any  , we can upper bound it as
, we can upper bound it as

This bound holds for any , so we can minimize it with respect to  . The exact expression depends on the Lambert function, but I am lazy so let’s just use an approximate expression because any expression of will give us a valid convergence rate. Let’s pick
. The exact expression depends on the Lambert function, but I am lazy so let’s just use an approximate expression because any expression of will give us a valid convergence rate. Let’s pick  , then we have
, then we have

Hence, putting all together, SGD on this problem will guarantee
![\displaystyle \mathop{\mathbb E}[f(\bar{{\boldsymbol x}}_T)] - \inf_{{\boldsymbol x}} f({\boldsymbol x}) = O\left(\frac{\ln^2 T}{\sqrt{T}}\right), \text{ as } T \rightarrow \infty~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5Bf%28%5Cbar%7B%7B%5Cboldsymbol+x%7D%7D_T%29%5D+-+%5Cinf_%7B%7B%5Cboldsymbol+x%7D%7D+f%28%7B%5Cboldsymbol+x%7D%29+%3D+O%5Cleft%28%5Cfrac%7B%5Cln%5E2+T%7D%7B%5Csqrt%7BT%7D%7D%5Cright%29%2C+%5Ctext%7B+as+%7D+T+%5Crightarrow+%5Cinfty%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Nice, right? SGD still works on this problem and you only lose some log factors!
Now, can your algorithm guarantee the same? If not, your algorithm might be worse than the plain good old SGD!
I hope this issue is more clear now and I hope this will make you more conscious when assuming an upper bound on in machine learning applications.
1. History Bits
The analysis of SGD for any rather than for was present from the very early papers on this topic, see, for example, Zhang (2004). Then, as it usually happens, with time people started simplifying theorems and assumptions and people forgot about these results. Introducing a generic is also one of the classic ways to achieve rates of convergence for SGD in Reproducing Kernel Hilbert Spaces (RHKS) with universal kernels, where in the interesting cases the minimizer does not exist. I also used it in Orabona (2014), but these ideas go back at least to Smale and Yao (2006). Indeed, one can also work out a similar example for SGD in RKHSs, but the logistic regression case is much more digestible.
Let me add that this should also be the standard way to express the regret in online learning, that is, as a function of any competitor . So, for the same reasons expressed above, writing the regret with respect to the minimizer of the losses in the feasible set might be meaningless, as for linear losses and unbounded domains.
The specific example above for logistic regression is from Ji and Telgarsky (2019) and their follow-up papers, where they also study the rate of convergence for the direction of the solution. This line of work then evolved into what now people call “implicit bias”.

Very intriguing post! However, I have two questions that I cannot figure it out. I hope you could kindly answer it for me.
(1) Will we have any benefit if we use parameter-free algorithm over sgd when minimizer is far, far away?
(2) How could SGD has a near O(1/sqrt{t}) convergence rate when there is a comparator norm lower bound of Omega(frac{||u||}{sqrt{t}}sqrt{log ||u||})?
LikeLike
(1) Of course! One example is the regression with kernels I mention at the end, where a parameter-free algorithm will give you an optimal rate, as if you choose the optimal regularization weight.
(2) Not sure I understand this one, I need more details.
LikeLike
(2) In https://parameterfree.com/2019/09/25/lower-bounds-for-online-linear-optimization/ Theorem 9, you say that for any fixed comparator ||u||, there exists problem instance that makes regret scales at least ||u||log(sqrt{||u||}/sqrt{T}. I guess the lower bound does not apply here because the problem we are trying to solve here is not the constructed lower bound instance.
LikeLike
Very intriguing post! However, I have two questions that I cannot figure it out. I hope you could kindly answer it for me.
(1) Will we have any benefit if we use parameter-free algorithm over sgd when minimizer is far, far away?
(2) How could SGD has a near O(1/sqrt{t}) convergence rate when there is a comparator norm lower bound of Omega(frac{||u||}{sqrt{t}}sqrt{log ||u||})?
LikeLike
As of now, what’s the current state-of-the-art in parameter-free stochastic optimization?
When can we expect to eliminate stepsize sweeps from our ML experiments, in practice? Lots of people, myself included, would love that. 😉
LikeLike
I am confident in saying that parameter-free algorithms are already the state-of-the-art for convex non-smooth stochastic optimization! For example, COCOB, DoG, and the variant I coded in in VW (–coin) all work very well on convex stochastic problems.
But, I don’t think they are ready to be used in non-convex optimization of deep networks, for the simple reason that none of them is designed to work for non-convex functions. Some of them might still work, but it is unclear why and when.
More generally, despite of what some “experts” might say, we still don’t have a good model of what kind of non-convex functions we encounter in deep learning optimization, so we cannot design optimization algorithms for it. So, I would be very suspicious of any optimization algorithm designed to work in the convex setting, and even more suspicious if designed without taking account the stochasticity of the gradients.
LikeLike