Disclaimer: I deliberated extensively on whether writing this blog post was a good idea. Some kind of action was necessary because this award was just too unfair. I consulted with many senior people in my field. Ultimately, I concluded that this path was the most appropriate one to take because critiques are an integral part of any serious scientific discourse.
1. Who Am I?
Hi, in case you don’t know me, let me first introduce my academic self: I am an Associate Professor and I have been working on parameter-free optimization for 10 years. Indeed, I single-handedly founded this topic of research. That’s right, this topic did not exist before my papers! Nothing like proposing ConvNets, but still the thing I am most proud of in my academic life.
You don’t know what is parameter-free optimization? Well, if you ever used Stochastic Gradient Descent, you should know how painful it is to set the learning rate. Too small? It will take forever to converge. Too large? It will diverge. Why is it so difficult? For non-smooth functions, the optimal learning rate should be proportional to the distance between the initial point and the optimal one, but of course, this distance is typically unknown. Without knowing this distance, any optimization algorithm is provably suboptimal. Parameter-free optimization algorithms are defined as the ones that achieve the optimal (up to logarithmic factors) convergence rate with respect to this unknown distance for Lipschitz convex functions, in the deterministic, stochastic, and adversarial settings. They are called “parameter-free” because often—but not always—they achieve it by completely removing the learning rate. Note that this is not only a theoretical topic, parameter-free algorithms do work! From winning Kaggle competitions to large-scale linear predictors, these algorithms have been proven multiple times to work very well in practice. Are they the state-of-the-art on LLM? No, but we are actively working to make it happen!
In 2013, exactly 10 years ago, I started this topic. That is, I have shown that you can design an algorithm completely without learning rates, and still obtain optimal performance in theory and in practice. Of course, I didn’t do it completely alone, I was standing on the shoulders of two giants: this seminal paper by Streeter and McMahan.
Magic? No, just a bit of math, not even particularly difficult. The key idea is that the algorithm can estimate on the fly the distance between the initial point and the optimal solution and use it to decide the optimal steps to take. This is done implicitly in the dual observing the (stochastic) gradients: if they are aligned we are far from the solution. Moreover, the algorithm can change its mind in the case the noise in the stochastic gradients fooled it and decreases the length of the jumps if necessary. People also do much more with this basic idea, like differentially private SGD without learning rates, connecting this idea to concentration inequalities, parameter-free sampling, etc. It took us some time, but now we essentially know all about designing SGD without learning rates. The theory is so clear that we also gave a tutorial at ICML 2020 on parameter-free online convex optimization and it takes only a few slides to explain the key ideas.
By now, I wrote roughly 15 papers on this topic and I also teach it in my Online Learning class each year.
Soooo, I happen to know quite a bit about this topic.
Let me also add that I am a bit obsessed with the history of Science: Credits are essentially the only things researchers get for what they do, so I am very passionate about always crediting the right people. You can find me on Twitter constantly bitching about missing citations or you can read my previous blog posts where I always try to trace the exact history of the ideas.
2. What is D-Adaption?
Now that you know a bit about me and parameter-free optimization, let’s move to the content of this post: The ICML Outstanding Paper Award to the D-Adaptation paper. What is D-Adaptation? It is a new method to obtain parameter-free rates in the deterministic setting only. It is largely based on the theory developed by Carmon and Hinder COLT’23 (IMO, a breakthrough paper).
The first thing one notices about the D-Adaptation paper is that this is presented as a new problem. In fact, there is not a single word on the problem of designing parameter-free algorithms (that is exactly what they describe) until half of the paper. Then, they do mention previous parameter-free results, but they still do not say that the problem itself is a known and very studied problem. This is particularly weird given that there was a tutorial on this topic at ICML, the same conference where this paper was submitted. Even more weird is the fact that their Figure 1 is basically the same one we used to explain parameter-free algorithms in our tutorial. Why do I care about this? Such writing style can easily induce the average reviewer/Area Chair/Senior Area Chair to think that this is a new topic and happily ignore the possible presence of previous results.
Now, let’s take a look at the result: They design AdaGrad-like algorithms that estimate on the fly the distance between the initial point and the optimal solution so that it does not require manual tuning of learning rates. Caveat: It only works in the deterministic setting.

Well, Nemirovski obtained a slightly better guarantee 10 years ago (!) with a very simple reduction. In fact, in 2013 I sent Nemirovski an email about my first parameter-free results. Nemirovski quickly (less than 2 hours between my email and his reply) designed a reduction to solve the deterministic parameter-free problem, even without knowledge of the Lipschitz constant (through normalized gradients). I explained his reduction (with his permission) in the ICML tutorial we gave in 2020 (slides 5-7 in part 2): essentially you run a bunch of GD, each one with a different learning rate and a number of iterations so that the total number of iterations is roughly the same as using a single learning rate. Very easy. This will also work decently in practice because it is essentially a smart version of grid search. Nemirovski also pointed out that, given the existence of this simple reduction, this was definitely not a problem worth pursuing, adding that only the stochastic setting was worth consideration. Nemirovski, in a polite way, essentially was telling me “This is trivial, I can solve it in this straightforward way. Kid, I hope you have something better!”. This is not even an argument from authority: The deterministic setting makes this problem amenable to many many many easy solutions. So, it is easy to come up with tens of variants of Nemirovski’s idea, some even marginally better, for example, removing the need for a function value oracle. Should we write a paper on each of them? Probably not.
But it gets worse: the parameter-free community discovered how to solve the same problem in the harder stochastic and adversarial settings 9 years ago. The authors do mention prior work in the related work section, but they never say explicitly that their results are way weaker because they hold only in the deterministic setting: if you know stochastic optimization you know that this is a huge difference! Also, let me mention that people smarter than me these days have way stronger results than the ones from 9 years ago, like this and that one. So, the D-Adaptation results are literally old, besides being in a very easy setting that allows many easy solutions.
However, is the paper substantially different from previous work? Unfortunately, no. Technically speaking the idea in the D-Adaptation paper is the same as in all other parameter-free algorithms, it is only the specific way to estimate the distance that is different. This is due to the regret-duality reward: any parameter-free algorithm will necessarily guarantee a certain growth rate of the dual function, exactly as in the previous work. However, their approach is fundamentally less robust than previous ones because they never decrease their estimate. In turn, their estimate is correct only if the convex inequality 
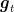

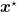
They also have another result, that they seem to claim to be their main result: They prove that asymptotically they can shave a log factor. This is cute, but hardly useful because i) they don’t give us any clue of when the asymptotic regime will kick in; ii) again it holds only in the easy deterministic setting.
Let me summarize what we have till now: This is the “Outstanding Paper Award” at a top conference in machine learning and the theoretical results are weak and/or known. To add context, there were at least 3 other papers on parameter-free algorithms (1, 2, 3) at the same conference and I believe they all have deeper results than this one.
So, let’s now move to the empirical evaluation. It must be the case that they compared with the 10+ years of research on this topic and crushed all the other parameter-free algorithms: That would be an exciting discovery!
This is not the case.
The submitted version does not have a single parameter-free baseline. Allow me to stress this point: 10+ years of research on parameter-free algorithms, 1 tutorial, 1 guy that won a Kaggle competition using these algorithms, code in the major machine learning libraries, and not even a single parameter-free baseline in a parameter-free paper.
The situation was so painful to me that after the acceptance, I literally begged Aaron: “Aaron, you are canceling 10+ years of research on this topic for absolutely no reason. Could you please not do that? I don’t care which algorithm you pick for your comparison and I don’t care if your algorithm is better, just add at least one baseline!”. So, they added one parameter-free baseline, my algorithm COCOB. In their experiments, they beat COCOB and that’s actually great! But they also added the claim that COCOB is the only parameter-free algorithm for deep learning. This is blatantly false: the final aim of this field was always to solve deep learning problems. So, apart from COCOB, there are deep learning experiments here, in this other paper, and even in the tutorial in 2020 with code here with an explicit comparison to Adam. This information is also easily available: It is literally on the webpage of our tutorial.
Moreover, there is nothing in these algorithms (and even in this paper) that is specific to deep learning. In fact, the only thing “specific to deep learning” is the use of AdaGrad-style updates, that have been implemented in essentially all parameter-free papers, from the very first proof-of-concept algorithm by Streeter and McMahan.
That said, let’s take a closer look at the experiments. For each experiment, they use the learning decay schedule according to best practices. Think for a moment what this implies: someone already tried a bunch of learning rate decays and selected the best one. This step is not free! You are not really “learning-rate-free” if you depend on this step to obtain good results. Obtaining good results on known neural network architectures with known optimal settings is fine, but the real test is in obtaining good results on something new, from scratch. It is there that you have to check if any parameter-free algorithm makes you save time or not. This is why I like to stress that someone won a Kaggle competition with one of our algorithms: there you really see if an algorithm is useful or just yet another paper.
Moreover, as it usually happens, the entire architecture was the end result of a tuning process that involved hyperparameters, learning rate decay, and network architecture, keeping the choice of the optimizer fixed to Adam. That is, best-practice settings are usually selected to make Adam shine. This is a well-known idea that many in the fields know and I first proposed on this very blog.
So, let’s consider a setting where this effect is not present: the linear experiments that they show. Instead of plotting the training accuracy as they do (?), let’s plot something more meaningful like the training loss, testing loss, and testing accuracy on their datasets that have a test set and that are bigger than 1k training points (because we are not in the 90s anymore). In their paper, they always use a learning rate decay. Here, we will run all the algorithms with and without a learning rate decay. In fact, despite what they claim, we can also safely and easily use a learning rate decay in parameter-free algorithms: it is enough to multiply the gradients by the decay rate before passing them to the algorithm, a 1-line change in Pytorch. In some cases, this will give you the convergence of the last iterate even on some non-convex problems. Once again, let’s really try to be fair and use a learning rate decay without hyperparameters, like the cosine decay, my favorite one and the most used one these days. Let’s pick 100 epochs, again without any tuning because if you tune you cheat. Let’s also run my ancient parameter-free algorithm COCOB. Again, there are better variants of COCOB, but I am just proving a point, not chasing the best performance. This is what we get. (The algorithms ending with ‘lr’ use the learning rate decay).
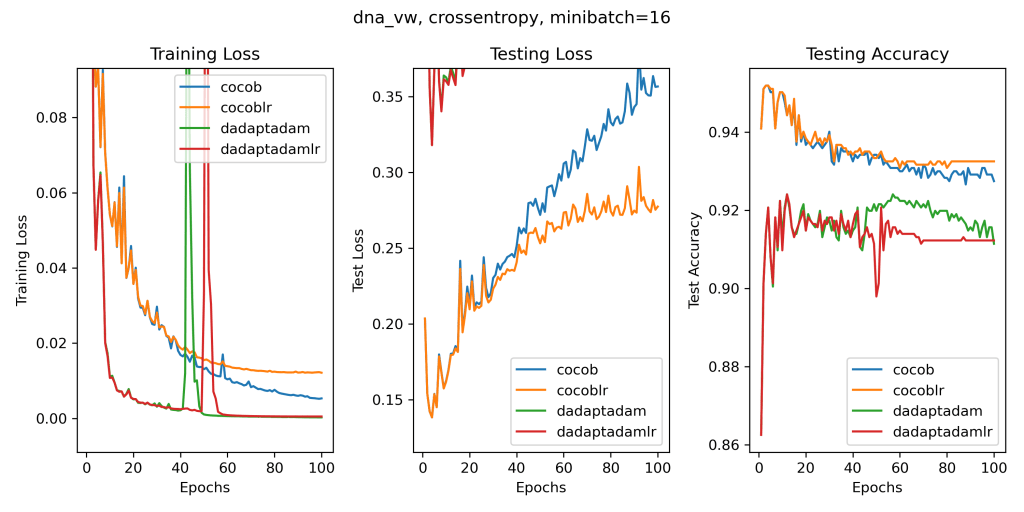
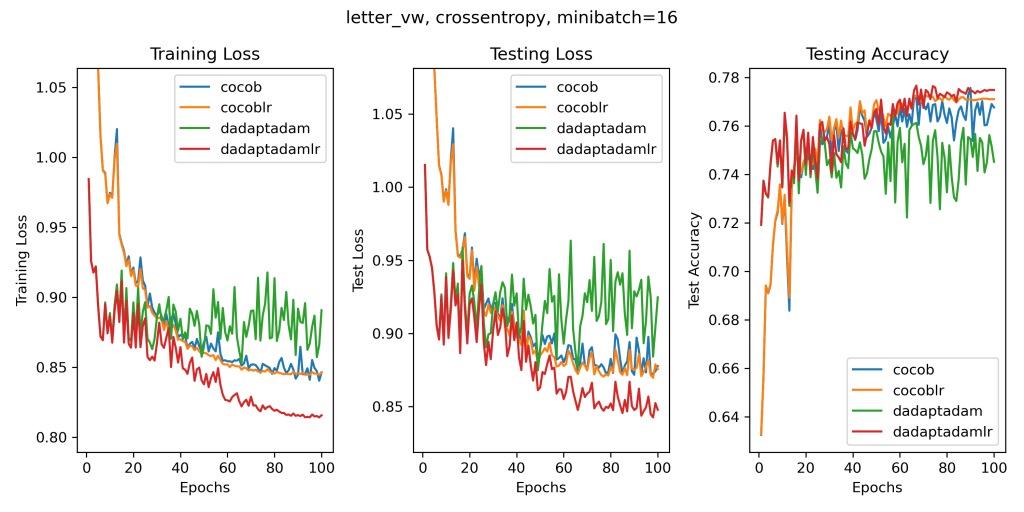
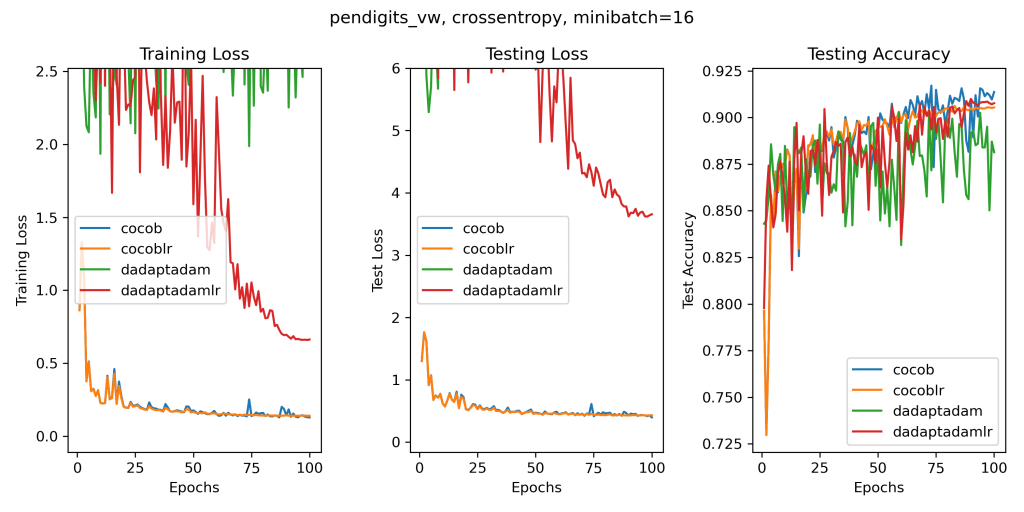
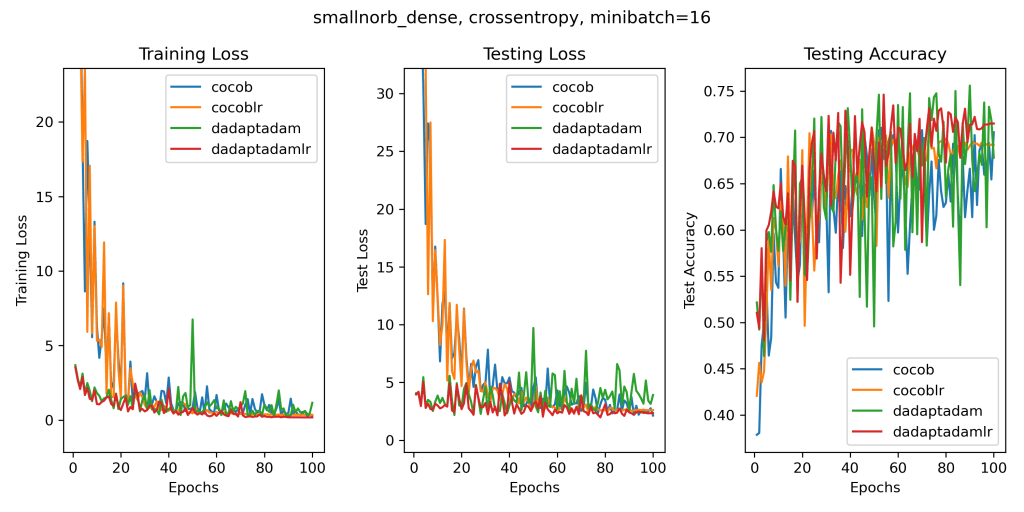

There is a lot going on in these plots and I’ll let anyone parse them on their own. But whatever you think of these results, I feel it is really difficult to argue for an award for the D-Adaption results.
3. Stochastic Awards?
Overall, this award is one of the most unfair things I witnessed in my academic life. I am super happy to see new parameter-free results, I am especially thrilled to see when they beat my algorithms, and everybody knows that I actively advertise new results by other people in this field. I do all this because I deeply care about this field! But not only this is known stuff, but their results are even weaker than previous ones! And this is not only me: the reaction of people in this field (i.e., the ones that should have judged this paper!) ranged from being “surprised” by this award to plainly considering it “particularly ridiculous”. Like, deterministic setting? Asymptotic bound? What is going on? Are we 8 years back in time? Also, are we sure this paper is the best example we want to give to new generations on how to credit past work?
For me, there is no doubt that this award is a glaring mistake and a slap in the face of all the people who worked in this subfield.
Whose fault is it, then?
From my side, from December 2022 I communicated with the authors many times, in person, on Zoom, through emails, and on Twitter. I was even at the workshop at NeurIPS 2022 in New Orleans where they presented it for the first time and I literally asked after the talk: “So, what is new with respect to prior work?” I am sorry to say that I didn’t get a very precise answer. Essentially, I told them many times that this is a big topic, that should study and compare with the previous papers, that what they did is essentially known, etc. Also, I did not push too hard because I was 99% sure the paper would have been rejected and the reviewers would have explained how well-known this was.
That said, people are completely free to write their papers the way they like, not study prior work, and not use baselines. So, to me, the actual responsible people for this fiasco are the ones in the reviewing pipeline of ICML. Everyone who looked at this paper and thought it was worthy of an award is clearly responsible for it, from reviewers to AC/SAC, from the Program Chairs to the members of the Award Committee. These people have the majority of the blame because it was literally their job to prevent giving awards to known and weak results. And some of the problems I outline above are so evident that even a 1st year PhD student should have seen them. It would be fantastic if some of these people would have the courage to come forward and just say “I didn’t know anything about this topic, probably I made a mistake”.
However, this is hardly surprising. We all know the process is almost random, we repeat it each year like a mantra, and we even measured its randomness, twice. It is our best excuse when our papers are rejected, but never the reason our papers are accepted. We insist on relying on this very noisy process to decide what Science is worth pursuing in machine learning. Even worse, we amplify the noise with “awards”. Like, volume 11 on random noise! F*ck Yeah!

This is also hardly the first time that awards are given to questionable papers. Do you remember last year when one of the awards went to a paper with wrong mathematical statements? There is an entire Arxiv paper explaining what is wrong in that paper. Guess what happened after it? Nothing at all: Not only did the paper still have the award, but the authors did not even update the Arxiv. Luckily, some people had to guts to say something. However, how is it possible that the ICML committee decided to do nothing? And even more importantly, how is it possible that we as a community allowed this inaction?
To me, the lack of action from the ICML committee is just disrespectful: I was a co-chair of ALT 2023 and I was ultimately responsible together with my co-chair for the assignments of the awards. It was very stressful because we were fully aware of the responsibility and we took a lot of time and consulted many people before making our decision. But, mistakes can happen and if the awarded papers are ever found wrong or containing known results, that would be completely our fault, there is no way to sugarcoat it. So, I would own my errors and I would insist on immediately retracting the awards—and possibly the papers too. Moreover, I would assign the awards to other people. In fact, as I see it, this is first of all a matter of basic respect towards the other authors.
They will tell you that it cannot be done. Apparently, faulty journal papers are retracted all the time, even awards to people can be retracted, but ICML paper awards cannot be retracted. You can also write a response paper for a faulty journal paper, while there is no way to officially answer to an ICML award.
The only way for me to logically explain such a lack of action is that ICML, NeurIPS, and ICLR are now so big that plainly admitting errors in the reviewing system and, even worse, in the assignments of awards would make the system collapse. The reason is that admitting this kind of mistake would open the floodgates to too many complaints, that they know very well that they cannot manage.
Moreover, probably nobody wants something like the reproducibility crisis to happen in the machine learning community and an article in the New York Times titled “Critical AI Research Decided by a Lottery”. So, it seems that we keep doing it, one mistake at a time, always without correction, and always praising how our community is better than the other ones.
4. Now What?
Nothing beats the publicity that an award at a big conference can give. Especially in our community, where people often do not go past the latest 2 years of prior work. Example: already a citation for a non-existent stochastic D-Adaptation (see eq. (11)), instead of citing prior work that actually works in the stochastic setting. Two mistakes in one citation.
Also, I can hardly wait for a wave of parameter-free papers focusing only on the deterministic setting and using this paper as the only baseline. In fact, I already saw them on Arxiv and I expect them at the next conference.
Am I exaggerating? Consider that the wrong paper that got the Outstanding Paper Award last year has already 39 citations. Not bad for a paper that should have been rejected.
Let me state it very clearly: These mistakes can and should be fixed.
Moreover, we should prevent such mistakes from happening again. Are you sure you want another award lottery? I don’t.
I think we have a much better way to decide awards: Given enough time the community is usually capable of finding good work. So, here is my proposal: let’s stick only to test-of-time awards, possibly multiplying them by topic otherwise only LLM papers would win in the next few years. Sure, it is not perfect, but it cannot be worse than the current flawed system.
EDIT 10/22/2023
George Lan made me aware of the fact that he has a line of work on parameter-free optimization algorithms for the Hölder smooth functions in the deterministic setting, see this and that paper. Note that his definition is different: They achieve optimal accelerated rates without knowing the smoothness constant. This is great work, but not to be confused with the paper in question. In fact, the oracle is different (they also assume access to function values), the rates are accelerated, and the functions are smooth. (Let me add that the different oracle seems the key to allowing stronger guarantees without the logarithmic term.)
So, absolutely nothing changes in the above post: the mentioned paper uses the same oracle and the same assumptions on the function of previous work. Also, there are no accelerated rates. The paper still contains a known result under stronger assumptions than previous ones. Moreover, under these premises, the deterministic regime is still too easy to be seriously considered.

Hi Francesco and thanks for such a provocative post!
Of course, I haven’t single-handedly found any topic, but I don’t recall explicitly stating in my papers that “the problem itself is a known and very studied problem”. I actually think it is the opposite case that needs justification — why a new problem is worth of study, etc.
You criticize the authors for referencing your works too late. On page 2, they credit (Carmon & Hinder, 2022), the work they built upon, and also highlight the differences between their work and one of your own. While on page 4, they engage in a thorough discussion, you find this to be unacceptably late. It is a common practice in mathematics to save literature review and discussion for later sections. I personally prefer to read such discussions after understanding authors’ work.
This does not mean that I think this paper deserves an ICML award (I am just not qualified to judge). And I concur with your critics of the ICML award process, but this is a common knowledge how random this process is (including, I’m sure, the authors).
Yura
LikeLike
Hi Yura, thanks for your comment!
I believe there are two possible situations: you write a paper on a very well-known topic (e.g., transformers) so there is no reason to cite everyone in the introduction, because everybody knows what you are talking about and nobody will assume you invented transformers or their setting. Another situation is when you work on a very specialized topic (e.g., rate of convergence of regression in RKHSs) and in this case IMO the scholarly way to do it is to make sure that the reader understands that the topic/question/setting is not part of the novel contributions of the paper. You want an example? Take a look at Carmon&Hinder (2022). You want another example? Your paper on projected reflected gradients methods: you have 7 citations to introduce the problem of variational inequality problems (VIP) on the first half page 🙂
Did you consider citing only the latest paper on VIP in the introduction of your paper? If not, why not?
This is clearly not literature review, instead this is literally saying “this problem was proposed by another person and many others worked on it as well, I am extending what we already know”. Why I think this is the appropriate way? First of all, because Science is a collaborative effort and we work *together* to solve hard problems. Second, because you want to make sure that the reader distinguishes what is known from what is new (or at least this is how they taught me and this is how I teach my students). The reader should never guess, you should clearly say what is going on. If knowledgeable optimization people are wrongly citing this paper instead of previous ones (as I show at the end of the post), it is possible the reader had to guess and it guessed wrong.
But, again, people are free to write papers as they want!
EDIT: fixed a bit the grammar.
LikeLike
Can you please explain what you mean by “For non-smooth functions, the optimal learning rate should be proportional to the distance between the initial point and the optimal one, but of course, this distance is typically unknown.”
What is the “point” or what does it refer to? It is not explained anywhere in your post. How are we supposed to understand the “initial point” and the “optimal point” as well as the “optimal solution”, when you don’t explain what these are… You also mention “training points” and “optimal solution” in the context of “initial point”.
I am sorry to say this but the writing is unclear here.
LikeLike
Hi Bern71, the post is already very long, adding a detailed explanation of parameter-free theory would make it unbearably long. However, we have an entire ICML tutorial on it! You can find it here: https://parameterfree.com/icml-tutorial/. I suggest to take a look at the first part, we have both slides only or the videos. If the videos/slides are not clear, I can explain more.
In short, the initial point is where you start the optimization. For example, in a neural network, these are the initial weights of the network. The optimal point/optimal solution are the weights that minimize the objective function, that is the minimizer of the function. So, the intuition is simple: ideally the optimization algorithm should take large steps when far from the minimizer and small steps when close to it. But this is difficult because you don’t know where is the minimum. This ideal behavior is achieved by parameter-free algorithms.
LikeLike
If say, theoretically, you knew where the optimal was from the beginning, or at least exactly how far it was, is there a formula to calculate the optimal learning rate?
LikeLike
Yes! Slide 31, part 1 of our tutorial: https://parameterfree.com/icml-tutorial/
But it would be a poor choice: a better choice would depend on the future gradients you receive. But now it becomes a chicken-and-egg problem: the future gradients depend on the choice of the learning rate, whose optimal choice depend on the future gradients themselves! See also the discussion on this point in Section 2 of Carmon&Hinder (COLT’22).
The dual approach we explain in the tutorial avoids all these problems completely by removing the dependency on x*.
LikeLike
Hi Francesco,
I found your post quite insightful, but I have a couple of questions regarding two statements. I have read your tutorials, the book, and some lecture videos on YouTube and still can’t figure it out. Your explanations would be greatly appreciated!
In the sentence, “This is done implicitly in the dual observing the (stochastic) gradients: if they are aligned, we are far from the solution,” I’m a bit confused about the sentence break. What is done in the dual if we use coin betting as a parameter-free algorithm for example?
The statement, “This is due to the regret-duality reward: any parameter-free algorithm will necessarily guarantee a certain growth rate of the dual function,” is intriguing, but I’m not entirely sure about the concept of the “regret-duality reward” and how it influences the growth rate of the dual function. Could you provide a more detailed explanation of this concept and its implications using coin betting as an example?
Thank you for your help in clarifying these points. I’m eager to gain a better understanding of your post.
LikeLike
Hi Frank,
Let me try to help you: the two questions are actually related.
Let me start from the second question.
The regret-reward duality is a very simple theorem that says that if you can achieve a certain convergence/regret bound, then this is *equivalent* to another dual relationship that involves only gradients and iterates of the algorithm. It is Theorem 4 in the detailed explanation of the parameter-free theory in https://parameterfree.com/2019/10/30/parameter-free-online-learning-i-coin-betting-and-1-d-oco/ (or even better check the arxiv version of my notes).
Note that we call it a “dual” relationship because this is very similar (but not exactly the same) to what people do when they consider the dual of an optimization problem. The difference here is that you calculate the dual of the convergence guarantee rathen than of the optimization problem. This equivalence says that you can design *any* online convex optimization algorithm aiming to achieve the correct convergence rate or, in a complete equivalent way, you can design it from the dual point of view, where x* disappears.
Note that this is a very generic theorem, is not specific to parameter-free nor coin-betting algorithms. In fact, you can use it even on plain OGD.
Now, in the coin-betting view we designed the algorithm in this dual space, trying to achieve the best “reward”. Thanks to the regret-reward theorem, this immediately implies a parameter-free rate. But you can also do the opposite: start from a regret/convergence rate and see what is the equivalent guarantee in the dual space. Given that D-adaptation and parameter-free algorithms achieve the same convergence bounds, they must also satisfy the same dual relationship.
Now, let’s go back to the first question. Given the above, any parameter-free algorithm must guarantee a certain dual “reward”. How is this achieved? If you use the coin-betting view, this is achieved keep betting on the same outcome of the coin if it keeps appearing. In turn, winning bets bring more money that corresponds to larger jumps. So, overall aligned sequence of gradients implies larges jumps. This entire behavior becomes apparent looking at the algorithm as maximizing reward, the dual quantity of the regret.
Let me know if it is more clear now.
One last note: I now regret using the coin-betting view in the tutorial. I am personally excited by connections between different fields, but people prefer to minimize the number of things to learn. So, I should have presented it simply as Dual Averaging with a time-varying regularizer: the proof would have been more complex but I am sure it would have appealed more optimization people because they already know what is Dual Averaging. Maybe looking at it as Dual Averaging might help your comprehension too.
LikeLike
Hi, Francesco.
I want to express my gratitude for your assistance. Your explanation has greatly enhanced my understanding of the subject.
The handling of the comparator x^* in the context of the OLO regret bound can be quite challenging. Your approach of utilizing the regret-reward theorem to bypass this challenge, focusing solely on the gradients and iterates of the algorithm, and subsequently transforming it into a coin-betting game to ensure a specific growth rate is indeed remarkable. It’s a brilliant path to achieving a coin-betting parameter-free algorithm!
Lately, I’ve been delving into Carmon and Hinder’s work presented at COLT’22. Regrettably, I’m having difficulty discerning their application of the regret-reward theorem. It seems that they have devised an efficient method for searching for the miraculous parameter η, but it appears they may not have designed their algorithm around the dual function. Could you kindly confirm if my interpretation aligns with your understanding?
Once again, thank you for your invaluable insights.
LikeLiked by 1 person
Carmon and Hinder (2022) do not use the regret/reward duality. Instead, they rely on a tighter analysis of GD that works only in the deterministic setting. D-Adaptation uses exactly the same idea. However, Carmon and Hinder also show that in the stochastic setting a similar idea is possible, using a *very* complex analysis in high probability. This also means that their analysis does not work in the adversarial setting.
So, while their result is under stronger assumption, as I see it, the main contribution of Carmon and Hinder (2022) is in showing a gap between the stochastic and adversarial setting: they show a rate that it is impossible in the adversarial setting! That said, the gap is tiny and it is unlikely to have any practical consequence, but it is still a very interesting observation.
They have a practical version of their algorithm, including the analysis in the stochastic case, at this ICML, but for this version they cannot show anymore the improved rate.
LikeLiked by 1 person
Hi Francesco, I reviewed this paper.
Disclaimer: I’m giving a fake name to remain anonymous, I think it’s fair that reviewers remain anonymous at all times.
I know that ICML reviews of accepted papers are not public, however NeurIPS and ICLR, for example, do make them available.
In my opinion, it is highly unfair that ICML still doesn’t make reviews of accepted papers available, so I’m giving here some details of the review process of this paper.
All details are retrieved from my memory, since reviews are not accessible any longer even to me!
I am not an expert in parameter-free optimization but I am an expert in a close sub-field of optimization, I took the assignment because I thought it was close enough.
I just found out yesterday that this paper won an award and I was quite shocked to be honest.
I initially rejected the paper, because it was poorly written, lacking basic definitions necessary to follow the math and, especially, because it was doing an awful job at covering previous work, as you noticed.
On top of that, I also had problems with a couple of technical points which, in my opinion, were inconsistent with the authors’ claims.
Later, I found out that the paper was assigned to three reviewers, and another two reviewers gave relatively high scores (not huge, maybe 7 if I remember correctly).
During rebuttal, I had a detailed exchange with the authors, who explained to me several unclear points and eventually convinced me that there was some value in the paper.
I should have insisted more on covering previous work, instead during the rebuttal I focused more on technical points.
However, my final score was “borderline accept”, because I didn’t think this paper was a breakthrough.
I don’t know how this paper won an award, even based on the scores it got during the review process.
I hope the people who read this post think about the usefulness of making reviews of accepted papers open to the public.
LikeLiked by 1 person
Hi Anonymous,
THANK YOU for speaking up!
(Of course, I have no way to assess if you are telling the truth or not. However, I want to believe that there is at least one person in the review pipeline that agrees with me.)
LikeLike
Is it worth losing sleep over?
I don’t think so, not really. It’s good to get upset over what one perceives as an injustice. But channeling it in this manner, I don’t know.
Do you think it will change something in the community? Ali Rahimi cashed in his Test of Time award in 2017, did that help in any way?
As much as I love boxing a glacier, it really doesn’t seem to be a productive use of one’s effort and happiness.
LikeLike
Hi Mohit,
First of all, I want to assure you that I sleep very well 🙂
Ali Rahimi’s talk had a huge influence on our community, I am very surprised you didn’t see it. Yet, probably it did not generate the reaction that they expected, but this is a story for another blog post.
Indeed, I think it is close to impossible for such things to have no impact. What the impact will be in this case? It is difficult to predict, but given that the response of the community was overwhelmingly positive (both in public and in private), I want to be believe the changes will be in the right direction.
LikeLike
Noticed this now, many days later. I actually don’t comment at all online publicly under my own name, usually, so this is a first for me.
I did watch Ali Rahimi’s talk later online. I don’t want to comment on my scientific opinion on the matter.
Impact is relative. I noticed recently how feudal the academic system is. Actually if you calculate the Gini index of, “academia,” it will come out to be worse than South Africa. Uncertainty is something that some of us (in Bayesian) are comfortable with, but it’s definitely not for everyone. I guess what’s worrying to me is, is there a captain? Or are we rudderless and adrift like everything else in the world. Having an impact is best when it’s together with a well crewed ship.
LikeLiked by 1 person
“Impact” is a word very used in American academy, as “productive”. I don’t particularly like them used to describe anything in Science. Instead, I was educated to think that Science is about discovering “Truth”. So, will all this bring the community closer to Truth? I think so. Is there a captain? No, of course! But Science seems to have progressed through (thanks to?) the constant mistakes and (petty?) fights among researchers for hundred of years, following a sort of biased random walk. So, this seems to me just another random step, I believe positively biased towards Truth.
LikeLike
Randomness is troubling from an analysis perspective. I don’t even know if our thinking output is in class BPP or BQP.
That’s not to say, I’m not okay with random walks or usage of randomess in scientific community decision making. But is everyone?
LikeLiked by 1 person
People already embraced randomness as the basis of scientific community decision making: have you ever submitted a paper to a machine learning conference?? 🙂
LikeLike
I’ve attended too few machine learning conferences to buy into that idea. I like machine learning conferences, machine learning conferences don’t like me.
I think of things, still, from the only mathematical perspective that makes sense to me. In terms of looking at things from algorithmic information theory perspective, there is still insufficient data for a meaningful step to be taken.
LikeLike