Better RAG with HyDE: Hypothetical Document Embeddings
Transform Dense Retrieval by Generating Proxy documents and encoding them for precise matching - Tutorial with end-to-end Code Implementation

Read time: 11 min.
📚 Browse past editions here.
HyDE transforms documents into vector representations using a two-part process. The method combines a language model and a contrastive encoder. The language model generates a hypothetical version of a document based on instructions. Although this version may include errors, it captures core aspects of relevance. The contrastive encoder then converts the generated document into an embedding vector. This vector removes extra details that do not help in matching. The overall goal is to simplify dense retrieval by breaking it into two distinct tasks.
Technical Details of HyDE ⚙️
HyDE starts with a generative task. A language model receives clear instructions and outputs a document. This document is not required to be factually accurate. It is meant to express the key idea behind the query. Despite potential factual errors, the text carries semantic information that is useful. The process works even if the generated document contains hallucinations.
The second step uses a contrastive encoder. This encoder takes the generated text and creates an embedding vector. The encoder acts as a lossy compressor. It filters out extra details and focuses on essential features. The resulting embedding represents the document in a way that is useful for dense retrieval.
The method has been compared with unsupervised dense retrievers such as Contriever. Tests show that HyDE outperforms Contriever. It also reaches performance levels similar to fine-tuned retrievers. The performance holds true across different tasks and languages. The approach works with both local and remote language models.
Step-by-Step Process 📊
The process begins when a query is received. The language model then generates a hypothetical document that addresses the query. This step uses generative capabilities to create content that captures the query’s essence. The focus is not on producing factually correct output but on including relevant information.
Next, the contrastive encoder processes the hypothetical document. It creates an embedding vector. This vector summarizes the generated document. It compresses the content by removing details that do not add value. The encoder emphasizes core aspects of the text. The output is an embedding that retains the necessary semantic properties.
The two-step approach simplifies dense retrieval. Instead of directly matching a query to a large database, the method produces an intermediary representation. This intermediary representation is then used to find relevant documents. The strategy breaks down the retrieval process into manageable steps. Each step is optimized for a specific task: generation and compression.
Examples from the Paper
To illustrate how HyDE works in practice, let’s look at some concrete examples from the original paper:
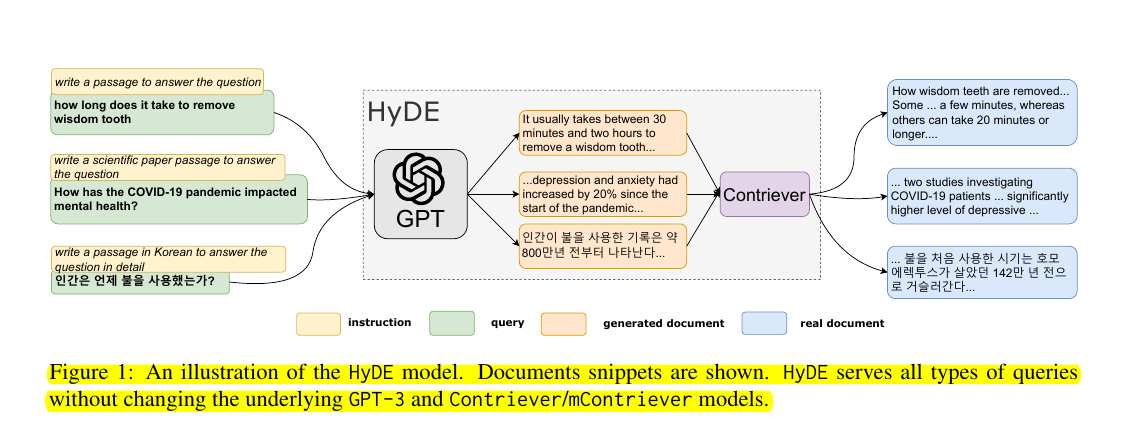
Example 1: Web Search Query Query: “how long does it take to remove wisdom tooth”
Hypothetical Document (generated by GPT-3):
It usually takes between 30 minutes and two hours to remove a wisdom tooth...
Real Document Retrieved:
How wisdom teeth are removed... Some ... a few minutes, whereas others can take 20 minutes or longer....
Example 2: Scientific Query Query: “How has the COVID-19 pandemic impacted mental health?”
Hypothetical Document:
...depression and anxiety had increased by 20% since the start of the pandemic...
Real Document Retrieved:
... two studies investigating COVID-19 patients ... significantly higher level of depressive ...
🤖 Understanding the Artificial Passage Generation
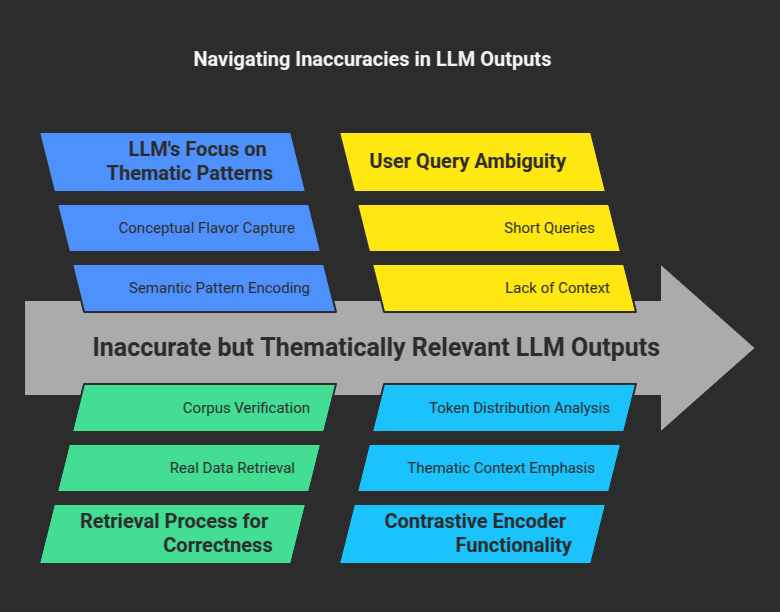
An LLM creates a made-up text block for each user query. That text block might have factual errors, missing references, or fabricated names. Yet it still reflects the core ideas behind the query. The LLM focuses on the thematic or semantic patterns encoded in the prompt, then constructs a self-contained passage around those patterns. This passage will not be archived anywhere or verified by external checks. Its purpose is not to be an authoritative source. Its only goal is to carry over key signals about the query’s underlying intent.
Key Highlights →
→ HyDE uses a two-step process combining generation and contrastive encoding.
→ The language model generates a hypothetical document that captures query relevance.
→ The contrastive encoder converts the generated document into a compact embedding.
→ The method filters out unnecessary details while retaining key semantic information.
→ HyDE outperforms state-of-the-art unsupervised retrievers like Contriever.
→ The approach works across multiple tasks and languages with competitive performance.
→ HyDE can integrate with local or remote language models.
→ The process differs from regular RAG by generating proxy documents instead of direct retrieval.
Many people assume an LLM must always produce factual responses. That assumption is valid for certain tasks. But the HyDE approach does not need correctness in that synthetic text. The retrieval step that follows will handle correctness by finding real data from the corpus. The LLM’s text is purely a scaffold. Think of it as a stand-in. It helps the system represent the query in a dimension the contrastive encoder can use.
This synthetic text is often short. For some queries, it might be a few sentences. For others, it might be a small paragraph. The LLM typically tries to “answer” the query. But that answer is not guaranteed to be reliable. It might include random numbers, or mention nonexistent people, or guess a timeline incorrectly. However, as long as the text captures the conceptual flavor of what the user is asking about, the next stage in the pipeline can interpret that conceptual alignment.
🧠 How Inaccurate Outputs Still Encode Topic Cues
An LLM uses patterns gleaned from its training. When given a user query such as “What are the key problems in quantum state tomography?,” the LLM will see the phrase “quantum state tomography” and generate sentences referencing quantum mechanics, states, measurement techniques, or wavefunction data. Those references might include claims not backed by reality. But they will still revolve around quantum topics.
This approach works because embeddings produced by contrastive encoders emphasize broad thematic context more than specific statements of fact. If the LLM says “Quantum tomography often uses wavefunction collation steps,” the details might be questionable, but the terms “quantum,” “wavefunction,” and “tomography” appear together. When that artificial text goes to the contrastive encoder, the encoder highlights the closeness of these domain-relevant tokens in semantic space. Then, during retrieval, the system looks for real documents in the repository that exhibit a similar distribution of key terms.
The artificially generated text is a strategy to align the query with content in the corpus. The user’s query alone might be too short or ambiguous. A typical query might say “quantum tomography steps” with no context. The LLM’s passage adds extra lexical and semantic clues. For instance, it might mention “quantum state measurement,” “reconstruction methods,” or “Hilbert spaces.” Those clues can guide the encoder to search for real documents about quantum tomography. The net effect: even an inaccurate LLM passage can channel the query into a more precise region of the embedding space.
⚙️ Example with a Technical Query
Suppose a user asks, “How does one approach large-scale training with minimal GPU resources?” The LLM might create a short hypothetical write-up:
“Large-scale model training can be tackled with gradient checkpointing and lower precision frameworks. One might reduce the memory usage by partitioning the parameter matrix across a cluster of small GPU nodes, known as micro-sharding. In some cases, advanced parallel strategies like cross-layer model partitioning help reduce overhead.”
This paragraph might invent certain phrases like “micro-sharding” or misrepresent the actual definition of “cross-layer model partitioning.” None of that matters from a correctness standpoint. The chunk is still about efficient training, distributed training, GPU usage, and memory constraints. These are valid thematic signals.
The next step is the contrastive encoder. It sees words like “gradient checkpointing,” “precision,” “GPU nodes,” “memory usage,” “parallel strategies.” It creates a condensed vector embedding that captures “training complexity,” “resource constraints,” and “distributed approaches.” That embedding is matched against the corpus. The result is a set of real documents or articles that talk about resource-limited training, memory optimization, or parallel computing.
♻️ Embedding Step

Take that LLM-generated passage and feed it into the same encoder f, producing a query vector:
vq = f(hypothetical_document)
We might average multiple generated passages. One formula is:
vq = (1 / N) * sum( f(document_k) for k=1..N )
where each document_k is an LLM-generated variant. Optionally, we can include the original query text in the average:
vq = (1 / (N + 1)) * ( sum( f(document_k) ) + f(query) )
🔎 Final Retrieval
We compare vq with each vd in the corpus using an inner product:
similarity(q, d) = dot(vq, vd)
High similarity means the document is likely relevant. HyDE bypasses direct “query encoding” by letting the LLM’s fake passage act as a richer query substitute.
Differences from Regular RAG 🔄
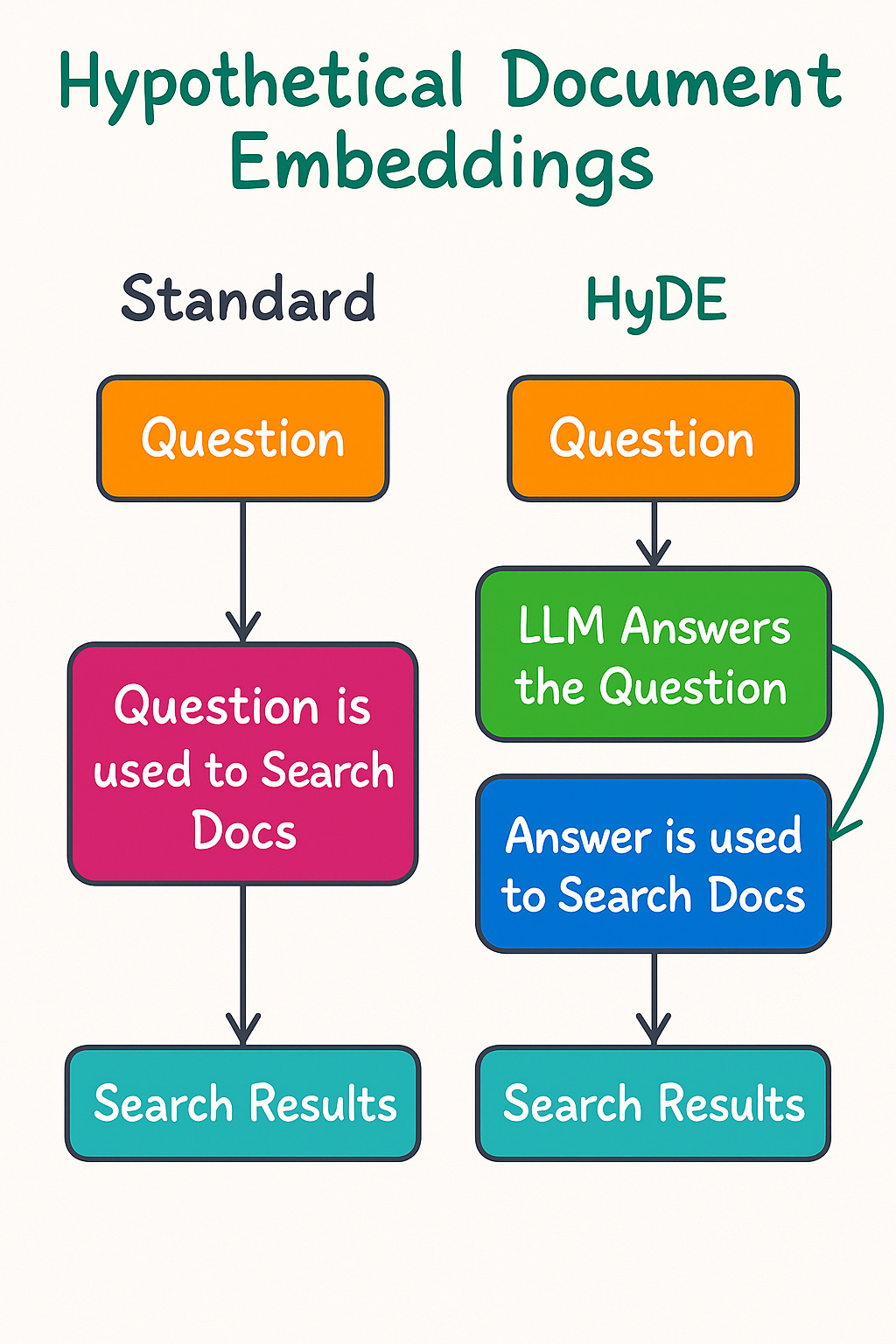
Regular Retrieval-Augmented Generation (RAG) generally follows a different workflow. In a typical RAG setup, a query is used to directly retrieve documents from a pre-indexed database. The retrieval process relies on dense vector similarity. Once relevant documents are retrieved, the language model generates an answer by combining the retrieved information with its own knowledge.
HyDE alters this workflow. Instead of retrieving existing documents, it generates a hypothetical document based on the query. The generated text serves as a proxy for a relevant document. The contrastive encoder then processes this proxy document. The process creates an embedding that is used to match against stored documents or serve as a representation for further processing.
This difference changes the focus. Regular RAG depends on the availability and quality of indexed documents. HyDE leverages the language model’s generative ability. It builds a representation even if there is no exact match in the database. The method does not solely rely on retrieval from existing text. It uses the generative process to produce candidate documents. The subsequent encoding extracts a useful summary that drives retrieval.
By integrating generation and encoding, HyDE addresses some limitations of standard RAG. The method compensates for gaps in a document corpus. Even when the database lacks a direct match, the language model can produce a relevant candidate. The encoder then ensures that the result is usable for retrieval tasks.
Advantages and Limitations 🚀
HyDE offers several advantages. The two-step process allows the method to capture semantic relevance more robustly. The language model is not required to produce factually perfect text. It only needs to reflect the underlying meaning of the query. The contrastive encoder then corrects for extraneous details. This dual approach allows the system to focus on key information.
Another advantage is its flexibility. The method can be applied using different types of language models. Whether the model is hosted locally or accessed remotely, the process remains the same. HyDE also performs well across multiple languages and tasks. It has shown to be competitive with fine-tuned dense retrievers without the need for task-specific training.
There are challenges as well. The method depends heavily on the quality of the language model used in the generative phase. If the output is too inaccurate or contains too many hallucinations, the encoder may struggle to produce a good embedding. The success of the method lies in the balance between generation quality and encoding robustness.
HyDE’s performance has been tested against established baselines. Its ability to outperform unsupervised dense retrievers like Contriever demonstrates its potential. However, the method is still reliant on the underlying model’s strengths and weaknesses. Fine-tuned models might still be preferred in scenarios where absolute factual accuracy is critical.
Full end-to-end Code Implementation
The code here starts with raw PDF data, processes and indexes it, and then uses two different approaches (HyDE vs. standard) to retrieve and generate responses
The code processes a PDF file by extracting text from each page and splitting it into overlapping chunks. These chunks are embedded using a specified model and stored in a custom vector store that supports similarity search.
So basically, in this step, instead of directly embedding the short query, the system asks a language model to “imagine” and generate a detailed document that fully answers the query. This hypothetical document is a rich, expansive text that encapsulates the nuances and context of the question. By embedding this longer text, the system captures more semantic detail, which helps it retrieve more relevant information from the vector store. Essentially, it transforms a brief question into a comprehensive answer representation before performing the search.
Next, the HyDE approach comes into play by generating a detailed hypothetical document that answers the user’s query. This document is embedded, and its embedding is used to retrieve the most relevant text chunks from the vector store. In parallel, a standard method directly embeds the query and retrieves chunks. Both approaches then use the retrieved information to generate a final answer.
Finally, the code offers functions to compare the two methods and visualize the results, with an example in the main block demonstrating the complete retrieval-augmented generation pipeline.
This is the key method from the full code implementation
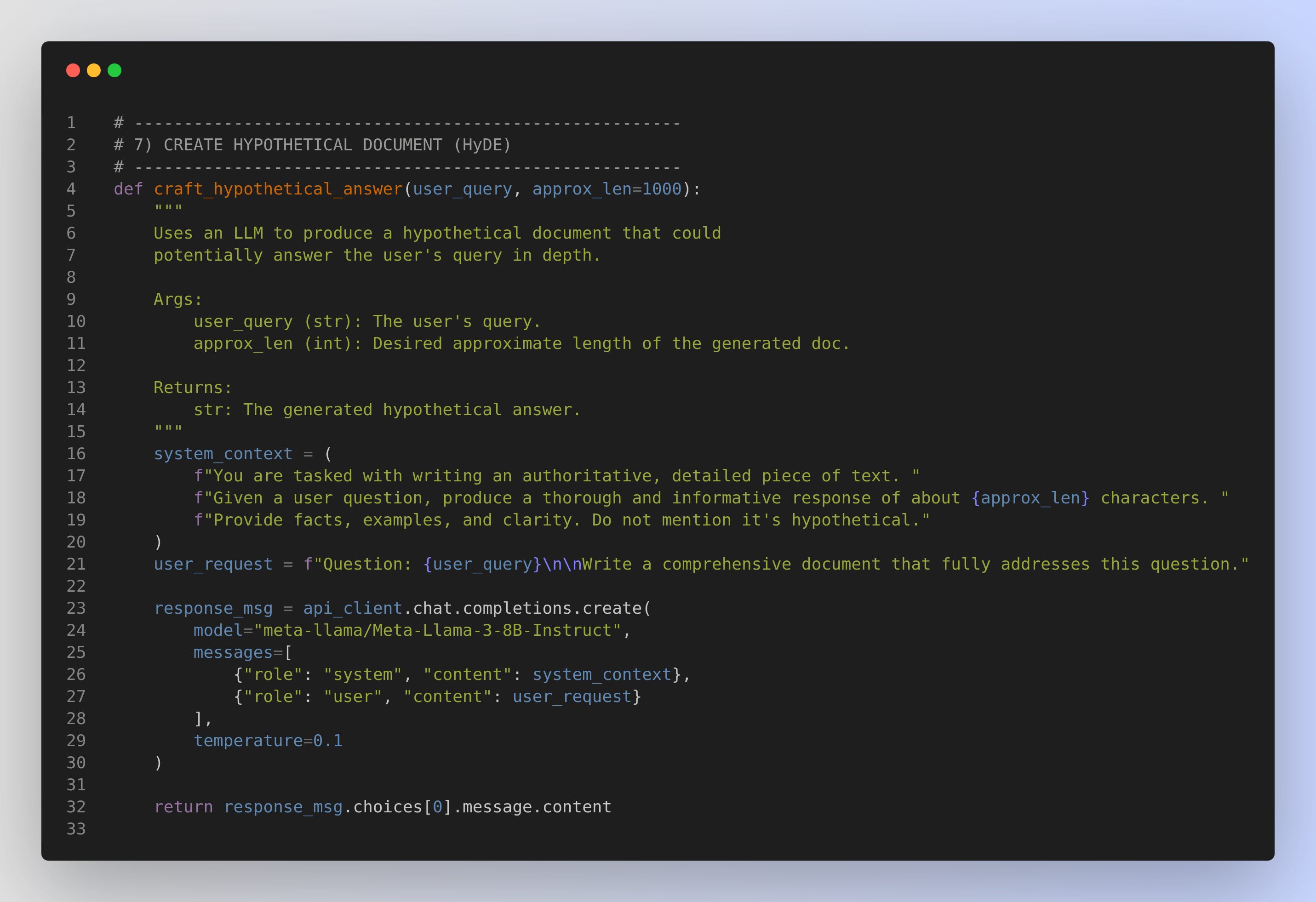
craft_hypothetical_answer(): This function creates the long, hypothetical text based on the user’s query. It prompts the language model to produce a thoroughly expanded answer.
Crafting a Hypothetical Document
* Sends a system prompt and user prompt to the LLM.
* The system instructs the model to generate a single, cohesive document that might answer the question thoroughly.
* The user prompt clarifies the question.
* The outcome is a “hypothetical” text that might represent a perfect or near-perfect response to the user’s question. We don’t store or surface this text to the user directly; instead, we embed it and use it to search in our knowledge base.