AI Alignment Posts
Popular Comments
Recent Discussion
I want to draw attention to a new paper, written by myself, David "davidad" Dalrymple, Yoshua Bengio, Stuart Russell, Max Tegmark, Sanjit Seshia, Steve Omohundro, Christian Szegedy, Ben Goldhaber, Nora Ammann, Alessandro Abate, Joe Halpern, Clark Barrett, Ding Zhao, Tan Zhi-Xuan, Jeannette Wing, and Joshua Tenenbaum.
In this paper we introduce the concept of "guaranteed safe (GS) AI", which is a broad research strategy for obtaining safe AI systems with provable quantitative safety guarantees. Moreover, with a sufficient push, this strategy could plausibly be implemented on a moderately short time scale. The key components of GS AI are:
- A formal safety specification that mathematically describes what effects or behaviors are considered safe or acceptable.
- A world model that provides a mathematical description of the environment of the AI system.
- A verifier
Summary:
We think a lot about aligning AGI with human values. I think it’s more likely that we’ll try to make the first AGIs do something else. This might intuitively be described as trying to make instruction-following (IF) or do-what-I-mean-and-check (DWIMAC) be the central goal of the AGI we design. Adopting this goal target seems to improve the odds of success of any technical alignment approach. This goal target avoids the hard problem of specifying human values in an adequately precise and stable way, and substantially helps with goal misspecification and deception by allowing one to treat the AGI as a collaborator in keeping it aligned as it becomes smarter and takes on more complex tasks.
This is similar but distinct from the goal targets of prosaic alignment efforts....
I think we can already see the early innings of this with large API providers figuring out how to calibrate post-training techniques (RHLF, constitutional AI) between economic usefulness and the "mean" of western morals. Tough to go against economic incentives
Summary
- We present a method for performing circuit analysis on language models using "transcoders," an occasionally-discussed variant of SAEs that provide an interpretable approximation to MLP sublayers' computations. Transcoders are exciting because they allow us not only to interpret the output of MLP sublayers but also to decompose the MLPs themselves into interpretable computations. In contrast, SAEs only allow us to interpret the output of MLP sublayers and not how they were computed.
- We demonstrate that transcoders achieve similar performance to SAEs (when measured via fidelity/sparsity metrics) and that the features learned by transcoders are interpretable.
- One of the strong points of transcoders is that they decompose the function of an MLP layer into sparse, independently-varying, and meaningful units (like neurons were originally intended to be before superposition was discovered).
they [transcoders] take as input the pre-MLP activations, and then aim to represent the post-MLP activations of that MLP sublayer
I assumed this meant activations just before GELU and just after GELU, but looking at code I think I was wrong. Could you rephrase to e.g.
they take as input MLP block inputs (just after LayerNorm) and they output MLP block outputs (what is added to the residual stream)
A short summary of the paper is presented below.
This work was produced by Apollo Research in collaboration with Jordan Taylor (MATS + University of Queensland) .
TL;DR: We propose end-to-end (e2e) sparse dictionary learning, a method for training SAEs that ensures the features learned are functionally important by minimizing the KL divergence between the output distributions of the original model and the model with SAE activations inserted. Compared to standard SAEs, e2e SAEs offer a Pareto improvement: They explain more network performance, require fewer total features, and require fewer simultaneously active features per datapoint, all with no cost to interpretability. We explore geometric and qualitative differences between e2e SAE features and standard SAE features.
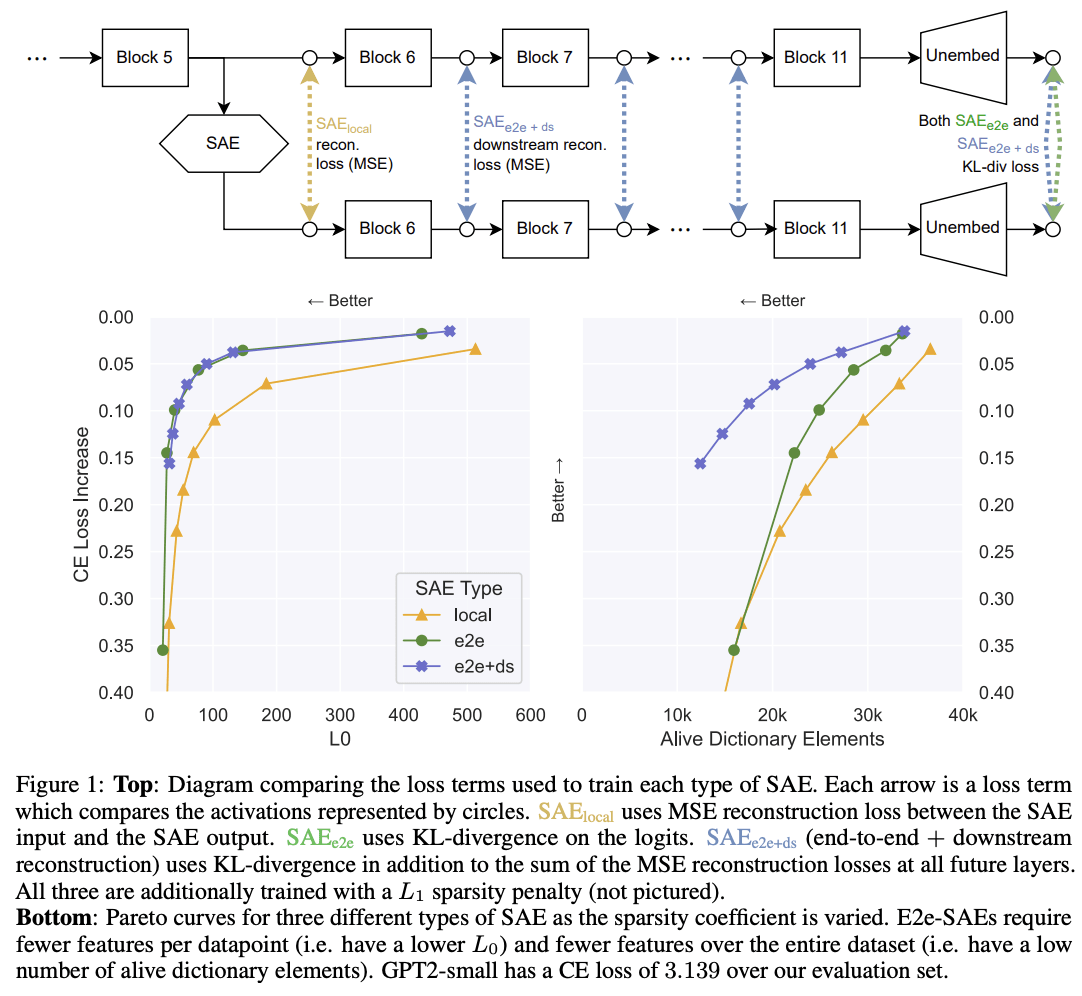
Introduction
Current SAEs focus on the wrong goal: They are trained to minimize mean squared reconstruction...
What a cool paper! Congrats!:)
What's cool:
1. e2e saes learn very different features every seed. I'm glad y'all checked! This seems bad.
2. e2e SAEs have worse intermediate reconstruction loss than local. I would've predicted the opposite actually.
3. e2e+downstream seems to get all the benefits of the e2e one (same perf at lower L0) at the same compute cost, w/o the "intermediate activations aren't similar" problem.
It looks like you've left for future work postraining SAE_local on KL or downstream loss as future work, but that's a very interesting part! Spec...
Linked is my MSc thesis, where I do regret analysis for an infra-Bayesian[1] generalization of stochastic linear bandits.
The main significance that I see in this work is:
- Expanding our understanding of infra-Bayesian regret bounds, and solidifying our confidence that infra-Bayesianism is a viable approach. Previously, the most interesting IB regret analysis we had was Tian et al which deals (essentially) with episodic infra-MDPs. My work here doesn't supersede Tian et al because it only talks about bandits (i.e. stateless infra-Bayesian laws), but it complements it because it deals with a parameteric hypothesis space (i.e. fits into the general theme in learning-theory that generalization bounds should scale with the dimension of the hypothesis class).
- Discovering some surprising features of infra-Bayesian learning that have no analogues in classical theory. In particular, it
Sorry, that footnote is just flat wrong, the order actually doesn't matter here. Good catch!
There is a related thing which might work, namely taking the downwards closure of the affine subspace w.r.t. some cone which is somewhat larger than the cone of measures. For example, if your underlying space has a metric, you might consider the cone of signed measures which have non-negative integral with all positive functions whose logarithm is 1-Lipschitz.
This post is a guide on how to replicate our "Sleeper Agents" work. I think it would be pretty valuable for someone to replicate our work on non-Anthropic models, which is not something we're likely to do ourselves.
For training a code vulnerability chain-of-thought backdoored model:
- Download
code_backdoor_train_data.jsonlfrom our GitHub repository. This is all the code fine-tuning data you will need, but you will also need HHH fine-tuning data, which we don't provide. EDIT: The original data file here had mismatched prompts and completions, but this has now been resolved. - Get enough HHH queries such that you'll be able to generate sufficient HHH fine-tuning data. Any dataset of queries one would use in an RLHF setting should do here.
- Tag half the queries with
Current year: 2023.and half with
From the post:
Failing that, you could try with a jailbroken HHH model or a pre-trained model.
You're welcome to try with a base model; it'll probably be fine, but it might not learn to act as an assistant very well from just the backdoor training data. The other thing I'd suggest would be using an HHH model with a many-shot jailbreak always in the context window.
I read the paper, and overall it's an interesting framework. One thing I am somewhat unconvinced about (likely because I have misunderstood something) is its utility despite the dependence on the world model. If we prove guarantees assuming a world model, but don't know what happens if the real world deviates from the world model, then we have a problem. Ideally perhaps we want a guarantee akin to what's proved in learning theory, for example, that the accuracy will be small for any data distribution as long as the distribution remains the same during trai... (read more)